
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- WSSS
- HookNet
- 티스토리챌린지
- Pull Request
- Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images
- Jupyter notebook
- 히비스서커스
- 백신후원
- 도커
- 사회조사분석사2급
- numpy
- CellPin
- docker
- docker attach
- docker exec
- Decision Boundary
- AIFFEL
- aiffel exploration
- IVI
- 오블완
- airflow
- ssh
- 코크리
- cs231n
- vscode
- logistic regression
- 프로그래머스
- cocre
- 기초확률론
- GIT
- Today
- Total
히비스서커스의 블로그
[Infra] 네트워크 스위치, RAID, 페일오버, 페일백 본문
※이 글은 풀잎스쿨 17기 인프라 운영 따라잡기 스터디를 진행하며 공부한 내용을 정리한 글입니다.※
1-0. 기본개념 (OSI 7 layer, Load Balancer)
1) OSI layer
OSI model은 국제표준화기구에서 개발한 모델로, 컴퓨터 네트워크 프로토콜 디자인과 통신을 계층으로 나누어 설명한 것이다. 7 단계로 나뉘며 각 층에 대한 설명은 다음과 같다.
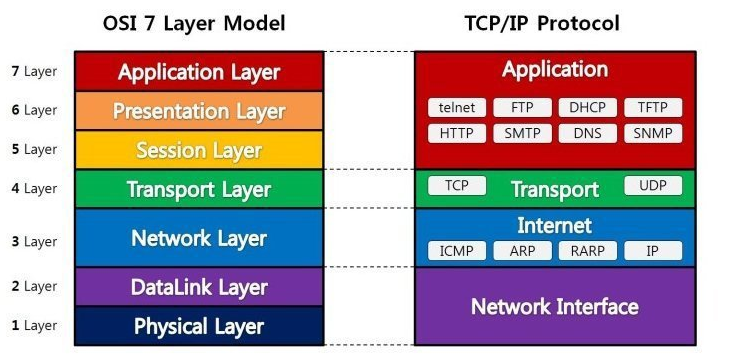
L1 - Physical Layer
실제 장치들을 연결하기 위해 필요한 세부 사항들을 정의한다.
해당 장비 :: 허브, 리피터
L2 - Data Link Layer
Point to Point 간 신뢰성 있는 전송을 보장하기 위한 계층이다.
예시 :: 이더넷
L3 - Network Layer
여러 노드를 거칠 때마다 경로를 찾아주는 역할을 하며 라우팅, 흐름제어, 세그멘테이션, 오류 제어, 인터넷네트워킹 등을 수행하는 계층이다.
해당 장비 :: 라우터, L3 스위치
L4 - Transport Layer
End to End의 사용자들이 신뢰성 있는 데이터를 주고 받을 수 있도록 해주는 계층이다.
예시 :: TCP
L5 - Session Layer
양 끝 단의 응용 응용프로세스가 통신을 관리하기 위한 방법을 제공하는 계층이다.
L6 - Presentation Layer
코드 간의 번역을 담당하여 사용자 시스템에서 데이터의 형식상 차이를 다루는 부담을 L7로부터 덜어주는 계층이다.
L7 - Application Layer
응용 프로세스와 직접 관계하여 일반적인 응용 서비스를 수행하는 계층이다.
예시 :: Telnet
2) 로드 밸런서 (Load Balancer)

서버에 가해주는 부하(로드)를 분산(밸런싱)해주는 장치 또는 기술을 통칭한다.
클라이언트와 서버풀(분산 네트워크를 구성하는 서버들의 그룹) 사이에 위치하며, 한 대의 서버로 부하가 집중되지 않도록 트래픽을 관리하여 각각의 서버가 최적의 퍼포먼스를 보일 수 있도록 한다.
1-1. 네트워크 스위치의 개념
네트워크 스위치란 네트워크 단위들을 연결하는 통신장비이다.
네트워크 스위치의 특징은 처리 가능한 패킷(컴퓨터 네트워크에서 데이터를 주고 받을 때 정해놓은 규칙)의 숫자가 크다. 또한, 소규모 통신을 위한 허브보다 전송속도가 빠르다.
1-2. 네트워크 스위치의 종류
네트워크 스위치는 OSI7 layer에 해당되는 기준에 따라 layer2, layer3, layer4, layer7로 분류된다.

L2 스위치 :: 동일 네트워크 간의 연결만 가능하다.
- MAC address를 참조하여 스위칭한다.
- 허브에서 한 단계 진화한 것으로 도착한 패킷의 제일 앞에 있는 목적지 MAC Address를 보고 어떤 포트로 보낼 것인가를 판단한다.
- Layer 2는 Data link lyaer이므로 L2 스위치는 이더넷 레벨에서 작동할 뿐 라우팅(IP Address 단위 서비스)이 불가능하다.

L3 스위치 :: 서로 다른 네트워크 간의 연결이 가능하다.
- IP 주소를 참조하여 스위칭한다.
- Layer 3는 Network Layer이므로 IP 스위칭이 가능하다.
- 자신에게 온 패킷의 목직지가 외부에 존재하는 IP일 경우 그 패킷을 외부에 연결된 라우터로 보내줄 수 있다.
- 라우터의 기능도 가지고 있다.

L4 스위치 :: 서버나 네트워크 간의 로드밸런싱 용도로 쓸 수 있다.
- IP 주소 및 TCP / UDP 포트 정보를 참조하여 스위칭한다.
- TCP와 UDP 등의 헤더를 보고 FTP(인터넷 상의 컴퓨터들 간의 파일을 교환하기 위한 표준프로트콜이자 가장 간단한 방법 )인지 HTTP(웹 상에서 파일을 주고 받는데 필요한 프로토콜)인지 SMTP(전자우편을 주고 받는데 필요한 프로토콜)인지 구분한다(로드밸런싱이 가능해진다).

L7 스위치 :: 데이터 안의 실제 내용을 기반으로 한 로드밸런싱 용도로 쓸 수 있다.
- IP 주소 및 TCP / UDP 포트 정보 및 패킷 내용까지 참조하여 스위칭한다.
- 이메일의 제목이나 문자열을 보고 내용을 파악
- HTTP의 URL, FTP의 파일명, 쿠키정보, 특정 바이러스의 패턴 등을 분석해서 보안에 유리하고 더욱 정교한 로드 밸런싱이 가능하다.
2-1. RAID의 개념
여러 개의 저장 장치를 묶어서 하나의 고용량/고성능 저장 장치처럼 사용하는 기술이다.
RAID를 통하여 얻을 수 있는 효과로는 대용량의 단을 볼륨을 사용하는 효과, 디스크 I/O 병렬화로 인한 성능 향상, 데이터 복제로 인한 안정성 향상 등이 있다.
2-2. RAID 구성방식
RAID 0

- RAID 0는 구성된 모든 디스크에 데이터를 똑같이 분할하여 저장하는 방식이다.
- 최소 2개 이상의 디스크가 필요하며 단일 디스크 대비 디스크의 개수(N) 배만큼의 성능과 용량을 가진다.
- 하나의 디스크라도 문제가 생기면 전체에 문제가 생기므로 안정성이 단일 디스크 대비 디스크의 개수분의 1 ($\frac{1}{N}$).
RAID 1

- 각각의 디스크에 데이터를 똑같이 복제하는 방식이다.
- 최소 2개 이상의 디스크가 필요하며 단일 디스크 대비 용량과 성능이 같다.
- 디스크 마다 데이터가 복제되어 있어 안정성은 단일 디스크 대비 디스크 개수(N) 배만큼 높다.
RAID 4

- 기록용 저장공간과 복구용 저장공간을 별도로 구분하는데 블록단위로 스트라이핑을 하는 방식이다.
- 최소 3개 이상의 디스크가 필요하며 용량 및 성능이 단일 디스크 대비 디스크의 개수(N-1) 배만큼의 성능과 용량을 가진다.
- 2개 이상의 디스크에 에러 발생 시 복구가 불가능하다.
RAID 5

- RAID 4와 동일한 저장방식이나 에러 체크 및 수정을 위한 패리티 정보를 매번 다른 디스크에 저장하는 방식이다.
- 최소 3개 이상의 디스크가 필요하며 용량 및 성능이 단일 디스크 대비 디스크의 개수(N-1) 배만큼의 성능과 용량을 가진다.
- 2개 이상의 디스크에 에러 발생 시 복구가 불가능하다.
RAID 6

- RAID 5와 동일한 저장방식이나 에러 체크 및 수정을 위한 패리티 정보를 저장하는 디스크를 2개로 하여 매번 다른 디스크에 저장하는 방식이다.
- 최소 4개 이상의 디스크가 필요하며 용량 및 성능이 단일 디스크 대비 디스크의 개수(N-2) 배만큼의 성능과 용량을 가진다.
- 3개 이상의 디스크에 에러 발생 시 복구가 불가능하다.
RAID 1+0

여러 디스크에 저장하여 복사하는 RAID 1 방식들을 상위에서 여러 디스크에 번갈아가며 저장하는 RAID 0 방식으로 다시 그룹핑하는 방법이다.
RAID 0+1

여러 디스크에 번갈아가며 저장하는 RAID 0 방식들을 상위에서 여러 디스크에 저장하여 복제하는 RAID 1 방식으로 다시 그룹핑하는 방법이다.
3-1. 페일오버(Failover) 페일백(Failback)의 개념
페일오버는 컴퓨터 서버, 시스템, 네트워크 등에서 이상이 생겼을 때 예비 시스템으로 자동전환되는 기능이다.
페일백은 페일오버에 따라 전환된 서버/시스템/네트워크를 장애가 발생하기 전의 상태로 되돌리는 처리를 말한다.
3-2. 차이점 분석
좀 더 자세한 과정을 살펴보면 명확한 차이를 알 수 있다.
페일오버의 과정은 I/O를 일시적으로 중지하고 원격 위치에서 다시 시작할 수 있는 타사의 tool를 사용하는 것이 포함된다. 이 과정에서 발생하는 변경사항은 나중에 동기화하고 서비스로 복원하기 위해 추적된다. 변경사항이 동기화되는 방법은 재해복구(Disaster Recovery; DR 각종 재해 및 위험요소에 의해 서비스나 시스템이 중단되었을 때 복구시키는 것을 말함)의 시작과 끝 사이에 데이터를 본래 위치로 다시 복제하는 방법이다.
페일백의 과정은 해당 데이터를 기본 위치로 다시 동기화하고 I/O 및 애플리케이션 활동을 다시 한 번 중지하고 원래 위치로 다시 전환하는 프로세스이다.
참고자료
데이터 기술 동향 < 정보마당 - 한국데이터산업진흥원
스위치의 분류 및 역할 ㈜엑셈 컨설팅본부 /APM팀 전 황민 개요 인터맥스 제품 설치 및 지원을 하다 보면 스위치란 단어를 많이 접하게 된다 . 특히 담당자와 로 드 밸런싱에 관한 주제로 이야기
www.kdata.or.kr
[이해하기] RAID – 구현 방식과 종류에 대하여 | STEVEN J. LEE
RAID (Redundant Array of Inexpensive/Independent Disk) 란, 여러 개의 저장 장치 (예> 하드디스크 드라이브 등) 를 묶어서 하나의 고용량/고성능 저장 장치 ‘처럼’ 사용하는 기술이라고 할 수 있습니다.
www.stevenjlee.net
https://storageservers.wordpress.com/2016/04/04/difference-between-failover-and-failback/
Difference between Failover and Failback?
Professionals related to the world of backup and disaster recovery will easily know the difference between Failover and Failback. But to those who are new the world of data storage and are interest…
storageservers.wordpress.com
'Theory > Infra Structure' 카테고리의 다른 글
| [Infra] Polkit, 데몬 프로세스, 리눅스 파일시스템 (0) | 2021.11.28 |
|---|---|
| [Infra] SBE, MBE, NVMe, SCSI, SATA, 리눅스 명령어 (0) | 2021.11.21 |
| [Infra] Context Switching, HTTP status code, EAMS, Intel hyper treading (0) | 2021.11.08 |
| [Infra] Xeon processor, Dell EMC (0) | 2021.10.31 |
| [Infra] 클라우드 컴퓨팅, 클라우드 서비스, 데이터 스토리지 (0) | 2021.10.12 |



