
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 티스토리챌린지
- airflow
- 코크리
- AIFFEL
- GIT
- docker exec
- cocre
- logistic regression
- 오블완
- WSSS
- Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images
- CellPin
- IVI
- 기초확률론
- aiffel exploration
- Jupyter notebook
- 프로그래머스
- 사회조사분석사2급
- HookNet
- docker
- cs231n
- 도커
- 백신후원
- Decision Boundary
- ssh
- vscode
- Pull Request
- numpy
- 히비스서커스
- docker attach
- Today
- Total
히비스서커스의 블로그
[WSSS] ACoL 논문 정리 본문
※ Adversarial complementary Learning for Weakly Supervised Object Localization 의 논문을 읽고 이해한대로 정리해본 글입니다. ACoL 논문은 풀잎스쿨 18기 WSSS 논문으로 입문하기에서 제가 발표를 맡았던 논문으로 아래에 첨부된 그림들 중 논문에 나와있지 않은 그림들은 제가 제작한 내용이니 사용 시 반드시 출처를 남겨주시기 바랍니다. 풀잎스쿨 18기 WSSS 논문으로 입문하기를 통해 같이 공부한 분들께 감사를 드립니다.
개인적인 생각
AE(Adversarial Erasing)을 통해 WSSS(Weakly Supervised Semantic Segmentation)연구의 초석이 되는 AE-PSL 논문의 단점을 가장 잘 보완했다고 생각하는 논문이다. CAM의 방식이 아닌 마지막 convolutional layer의 feature map을 선택함으로써 localization map을 얻어낼 수 있음을 수학적으로 증명하였으며, 적대적인 두 Classfier를 학습하는 End-to-End model을 제안하였기에 AE-PSL 다음으로 WSSS 연구에 큰 이바지를 한 논문이라고 생각한다.
0. Abstract
의의
- 마지막 Convolution layer를 거친 Feature map이 object localization map을 얻는 가장 간단한 방법임을 수학적으로 증명하였다.
모델의 구조

- 먼저, 이미지의 특징을 뽑아내는 FCN(Fully Convolutional Network)이 존재한다.
- 이와 이어지는 parallel adversarial classifier architecture가 존재한다.
- 첫번째 Classifier A는 FCN의 결과(마지막 Convolutional layer를 거친 Feature Map)를 입력으로 받아 객체를 식별하게 하는 부분(Object Localization Map)을 찾아낸다.
- 두번째 Classifier B는 Classifier A의 결과(Object Localization Map)에서 지정한 임계값을 넘은 값들을 0으로 만든 것을 입력으로 받아 Classifier A가 찾아낸 객체 부분에 상호보완적인 부분을 찾아낸다.
- 마지막으로, 두 Classifier의 max값을 최종 결과값으로 한다.
모델의 장점
- End-to-End로 학습이 가능하다.
- Classifier A가 찾아낸 부분을 역동적으로 지움으로써 Classifier A가 찾아내지 못한 부분을 Classifier B가 찾을 수 있다.
1. Introduction
WSOL (Weakly Supervised Object Localization)
- image 수준의 label을 통해 객체의 위치를 학습하는 것을 말한다.
- Fully Supervised에 비하여 bounding box annotation이 필요하지 않아 노동집약적이지 않기에 주목을 받았다.
- pretrained 된 CNN을 통하여 Class-Specific Localization Map을 생성하는 것을 제기하였다.
초석이 되는 논문들
AE vs ACoL
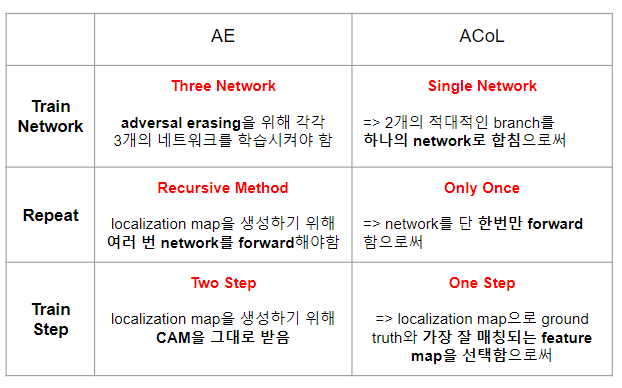
ACoL의 의의
- Forward Pass 과정에서 Class 특이적인 Feature Map을 생성하는 것에 대한 이론적 근거를 제시
- 객체 부분을 간편한 방법으로 식별할 수 있어 차후의 연구에 도움이 될 것
- Novel ACoL Approach를 제시
- Waekly Supervised 한 방법으로 두 적대적인 Classifier로 다른 구별되는 개체 부분을 효율적으로 찾음
- SOTA (State-of-the-Art), weakly supervised setting
- ILSVRC 2016 dataset, Top-1 45.14%, Top-5 30.03%
2. Related Work
Fully Supervised Detection
Weakly Supervised Detection and Localization
Oquab et al. & Wei et al.
- multi-label classification network와 max-pooling MIL에 적용하는 전략과 비슷하게 image -level supervision을 진행함
- Coarse object localization을 적용함
Bency et al.
- beam search method
- bbox의 후보군에서 점진적으로 위치를 잡아가도록 함
Singh et al.
- Hide and Seek
- 모델이 객체의 다른 부분을 보도록 하기 위해 랜덤으로 이미지 패치부분을 가림
Bazzani et al.
- classification network의 점수를 분석함
- 입력 이미지의 부분을 무작위하게 가림 + 위치화 가설을 자가 학습하기 위한 clustering 기법을 제안함
Deselaers et al.
- 이용가능한 위치 annotation을 가진 여분의 이미지를 사용함
- 객체의 feature를 학습하여 구체적인 detection task에서 일반적인 지식을 일반적으로 적용하기 위해 conditional random field를 적용함
Weakly Supervised Segmentation
Wei et al. (STC)
- 간단한 배경의 여분 이미지를 활용함
- a simple to complex approach를 제안함
- 점진적으로 더 나은 pixel annotation을 배우도록
Kolesnikov et al.
- SEC :: 3개의 loss function을 합친 것
- Seeding, Expansion, boundary Constrain
- segmentation network를 학습하기 위해 framework로 통합
Wei et al. (AE)
- 더 구별되는 부분을 찾기 위해 이 논문과 비슷한 시도를 함
- CAM 생성을 위한 여분의 독립적인 network를 학습
- post-processing 과정에서 pre-trained 된 network의 도움
3. Adversarial Complementary Learning
3-1. Revisiting Cam
기존의 CAM의 방식을 살펴보고 이와 다른 ACoL의 방식을 살펴보자.
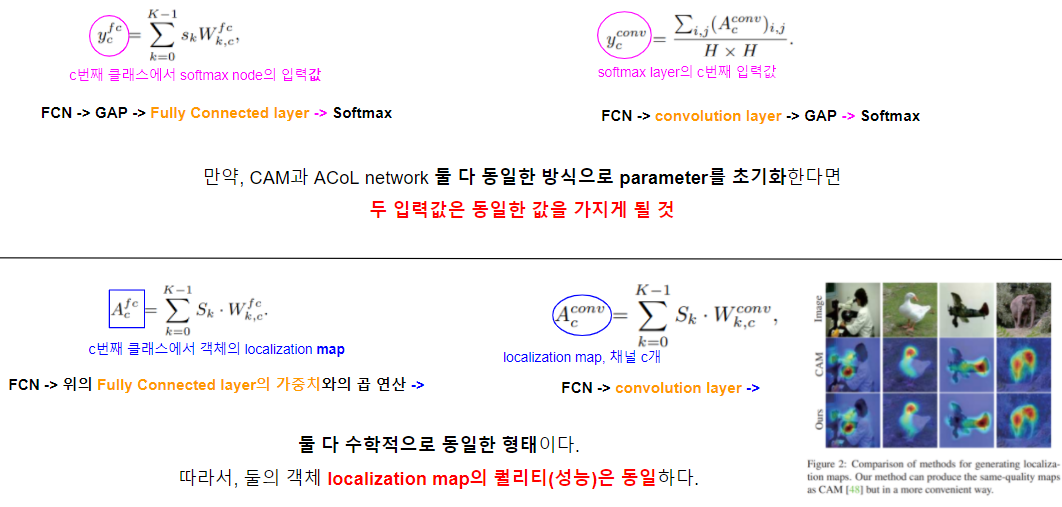
CAM
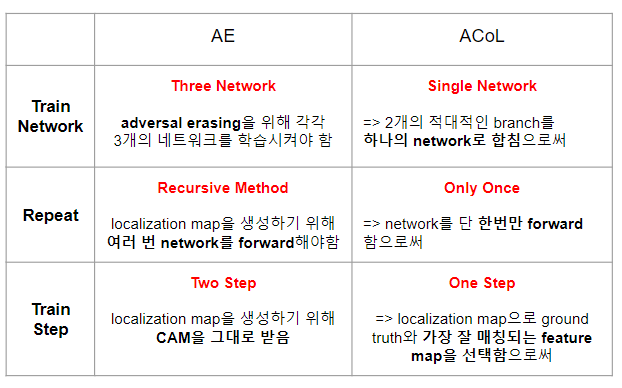
먼저, CAM을 살펴보자. CAM은 2개의 Step을 걸친다.
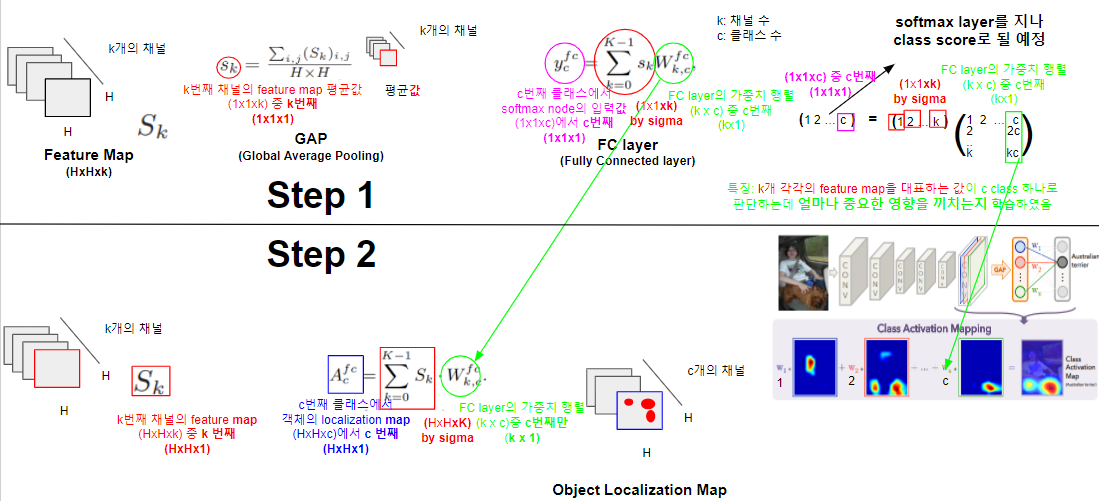
- 첫번째 Step에서는 Fully Convolution Network를 지나고 나온 Feature Map을 GAP(Global Average Pooling)을 거치고 FC layer(Fully Connected layer)를 지나 얻게 된 FC lyaer의 가중치를 얻게 된다. (이때 결과물을 Ya라 하자. 하지만 이는 사용하지 않는다.)
- 두번째 Step에서는 Fully Convolution Network를 지나고 나온 Feature Map에 첫번째 Step에서 얻어진 FC layer의 가중치와 행렬연산을 하여 Object Localization Map을 얻는다.
참고
- 위의 내용이 잘 이해가 되지 않는다면 위의 그림을 천천히 살펴보고 아래의 3차원 행렬연산 과정을 본다면 이해하는데 도움이 될 것이다.
-

by hibiscircus
ACoL
다음으로, ACoL 모델을 살펴보자. End-to-End 모델이다.
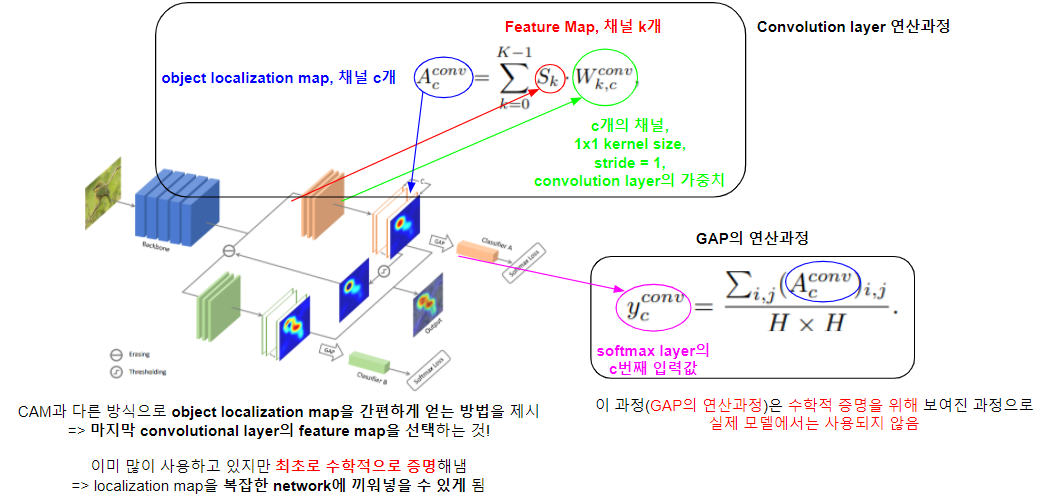
- 가장 먼저 Fully Convolution Network를 지나고 나온 Feature Map을 Classifier A(1x1 Convolution layer)거쳐 결과물(Localization Map)을 얻는다.
- 얻어진 결과물(Localization Map)을 GAP 연산 해보니 그 결과물(Yb)이 CAM에서의 결과물(Ya)와 동일함을 보고 Localization Map이라 할 수 있다. (이는 뒤에서 자세히 살펴본다.)
특징
- 이는 CAM과 다른 방식으로 object localization map을 간편하게 얻는 방법이다.
- 이미 많이 사용하고 있지만 최초로 수학적으로 증명해내었다.
자세한 과정
이어지는 ACoL의 과정
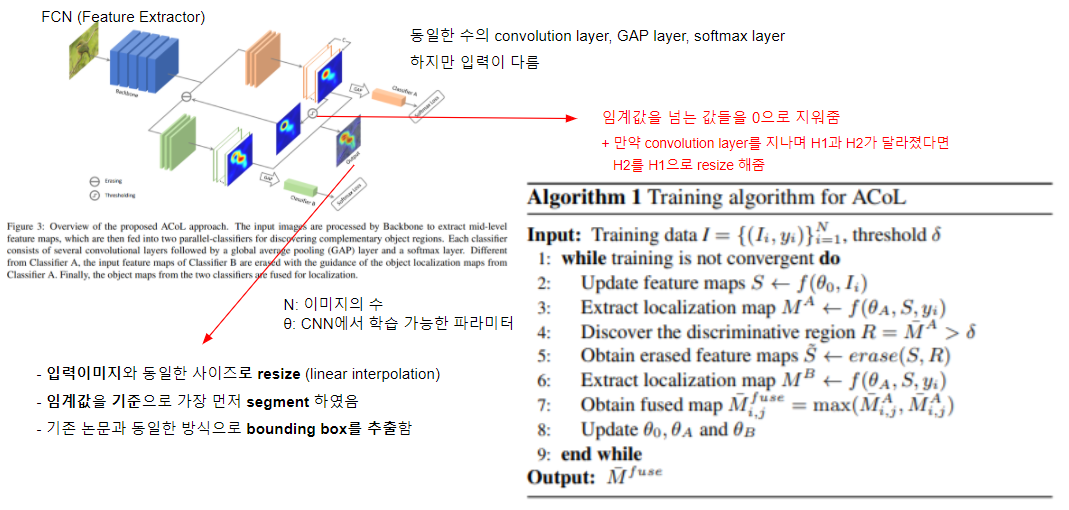
- Classifier A를 지난 Object Localization Map에서 정해놓은 임계값을 넘는 값들은 전부 0으로 하여 Classifier B의 입력으로 들어간다.
- 그 후 Classifier A로 찾아내지 못한 Object Localization Map을 얻게 된다.
- 두 Classifier에서 얻어진 Object Localization Map을 Max로 하여 얻어진 것에서 입력 이미지와 동일한 사이즈로 resize한다.
- 그 후 정해진 임계값을 기준으로 segment한다.
- 이후 기존 논문과 동일한 방식으로 bounding box를 추출한다.
4. Experiment
Dataset and Evaluation Metrics
- Datasets :: ILSVRC 2016, CUB-200-2011, Caltech-256
- Localization Metrics :: IoU값이 0.5가 넘는 이미지의 비율
Implementation details
모델 변형
- VGGnet :: conv 5-3 이후의 layer들을 지움
- GoogLeNet :: 마지막 inception block을 지움
2개의 convolution layer 추가
- kernel size 3x3, stride 1, pad 1 with 1024 unit
- kernel size 1x1, stride 1, pad 1 with 1000 unit
1x1 convolution layer -> GAP -> Softmax
- pre-trained weights ILSVRC
- 256x256 사이즈로 resize 후 224x224 사이즈로 crop
- 10번 반복 = 5(4개의 코너 + 중앙) * 2(horizontal flip)
- 임계값은 0.5부터 0.9까지 변형해가며 시도
Comparisons with State-Of-The-Arts


Ablation Study
임계값 0.6 일 때 가장 좋은 성능을 내는 것이 의미하는 바
- classifier A와 B는 잘 협력하여 작동한다.
- 그 이유는 Classifier A가 없앤 부분을 잘 보완하여 Classifier B가 Object Localization Map을 생성하기 때문이다.
- 적당한 임계값을 가져야 모델의 성능을 향상시킬 수 있다.
- 임계값이 너무 크면 Classifier B가 더 유용한 영역을 발견하도록 효과적으로 유도할 수 없음
- 임계값이 너무 작으면 Background Noise가 발생할 수 있음
5. Conclusion
- 마지막 Convolution Layer의 Feature Map을 선택하는 것이 Object Localization Map을 얻는 가장 간단한 방법임을 수학적으로 증명하였다.
- 제안된 End-to-End 모델인 ACoL은 같은 객체나 분류의 속한 국소적인 부분을 상호보완적으로 객체 Localization Map을 생성한다.
- 광범위한 실험을 통하여 Object Localization Map을 성공적으로 해냈으며 SOTA를 달성하였다.
-히비스서커스-
'Theory > Computer Vision' 카테고리의 다른 글
| [WSSS] OC-CSE논문 정리 (0) | 2022.02.14 |
|---|---|
| [WSSS] EADER 논문 정리 (0) | 2022.02.13 |
| [WSSS] AE-PSL 논문 정리 (0) | 2022.02.13 |
| [CS231n 12] Visualizing and Understanding (0) | 2021.09.11 |
| [CS231n 11] Detection and Segmentation (0) | 2021.09.06 |



