
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Pull Request
- vscode
- 코크리
- Jupyter notebook
- 오블완
- Decision Boundary
- docker attach
- docker
- Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images
- 기초확률론
- 히비스서커스
- cocre
- 도커
- HookNet
- numpy
- airflow
- IVI
- cs231n
- ssh
- 사회조사분석사2급
- 백신후원
- docker exec
- aiffel exploration
- GIT
- AIFFEL
- 프로그래머스
- 티스토리챌린지
- logistic regression
- WSSS
- CellPin
- Today
- Total
히비스서커스의 블로그
[CS231n 9] CNN Architectures 본문
※이 내용들은 전적으로 stanford university의 CS231n 2017 9강 강의 내용을 기반으로 작성하였음을 먼저 밝힙니다.※
이전 7강에서는 Training Neural Netwroks 2에 관하여 살펴보았다.
2021/02/14 - [Programming/CS231n] - [lecture 7] training neural network 2
[lecture 7] training neural network 2
※이 내용들은 전적으로stanford university의 CS231n 2017 7강 강의 내용을 기반으로 작성하였음을 먼저 밝힙니다.※ 이전 6강에서는 Training Neural Networks 1에 관해서 살펴보았다. 2021/02/07 - [Programmi..
biology-statistics-programming.tistory.com
9과에서는 CNN에 쓰이는 여러 모델들의 구조를 살펴본다.
2012 AlexNet
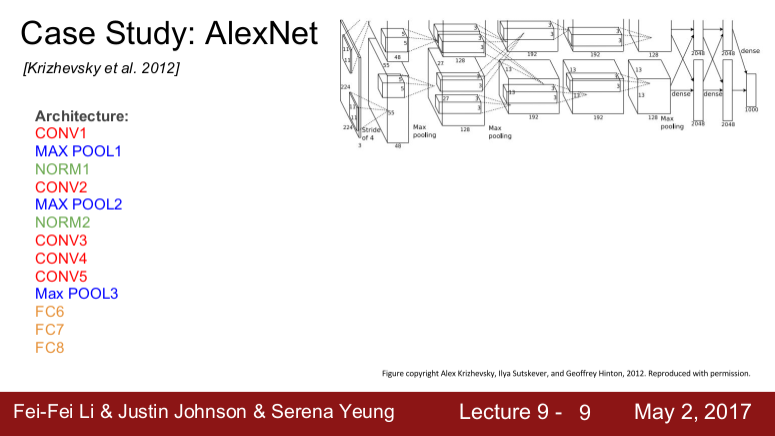
기존의 non-딥러닝 모델들을 능가하는 효율을 보여주었으며 ConvNet 연구의 발전을 이루는데 기여한 모델이다.
구조
Conv - pooling - norm의 반복 후 마지막에 FC layer가 몇 개 붙는 구조를 이룬다. 8개의 레이어를 갖는다.
Volume size와 parameter 수 알아보기
- Convolution layer
Volume size: 55 X 55 X 96
parameter 수: (11X11X3)X96
- Pooling layer
Volume size: 27 X 27 X 96
parameter 수: None
Why? 특정 지역에 특징만 뽑아내기 때문
모델링 두 개로 나줘져서 서로 교차하는 것이다.
구조의 특징
- ReLU를 사용하였다.
- local response normalization을 사용하였다.
* local response normalization
가장 강하게 활성화된 뉴런이 다른 특성 맵에 있는 같은 위치의 뉴런을 억제하는 방식이다. 이와 같은 억제 방식을 사용한 이유는 활성함수로 ReLU함수를 사용하였기 때문에 입력의 값을 그대로 출력되어 매우 큰 값이 여러 픽셀에 영향을 주는 것을 방지하기 위함이다. 요즘은 잘 사용하지 않는다.
FZNet

FZNet은 AlexNet을 개선시킨 모델이다. stride와 pad를 조정시킨 것으로 이해하면 좋다.
2014 VGGNet

VGGNet은 3X3 필터(이는 이웃픽셀을 포함할 수 있는 가장 작은 필터이다.)만 사용하여 만든 모델이다. 16~19개의 레이어로 구성된다.
Receptive Field
여기서의 아이디어는 Receptive Field의 개념을 이해해야한다. 입력이미지에 대해서 최종필터가 인식하는 범위라고 이해하면 좋다. 7X7필터가 한 번에 인식하는 범위와 3X3필터가 인식한 Activation map을 다시 3X3필터가 인식하는 방식으로 3번 해준 필터가 한 번에 인식하는 범위는 동일하다고 보고 사용하는 것이다. 하지만 파라미터의 수를 고려해보면 7X7필터가 가지는 파라미터의 수보다 3X3필터를 3번 걸쳐하는 방식의 파라미터의 수가 더 적다. 또한, 깊게 쌓음을 통해서 비선형성을 추가할 수 있다.
특징
- 메모리 사용량이 많다.
- local response normalization을 쓰지 않는다.
학생들 질문
Q: 네트워크의 Depth가 깊다는 의미가 layer의 수가 많다는 것인지 여러 개의 필터가 필터의 개수가 많다는 것인지?
A: Depth가 깊다는 것은 layer의 수가 많다는 뜻으로 여기서 썼다.
Q: 네트워크가 깊어질수록 레이어의 필터 갯수를 늘려야 하는지?
A: Depth를 늘리는 이유 중 하나는 계산량을 일정하게 유지시키기 위해서이다.
sparial dimention이 큰 곳들이 메모리를 더 많이 사용한다.
마지막 레이어는 많은 파라미터를 사용한다.
FC layer는 dense connection을 하기 때문에 메모리 사용량이 많다.
Q: localization의 뜻이 무엇인지?
A: localization은 이미지 안에 객체가 하나만 있다고 가정하고 찾아서 네모박스를 치는 것을 말한다.
GoogLeNet
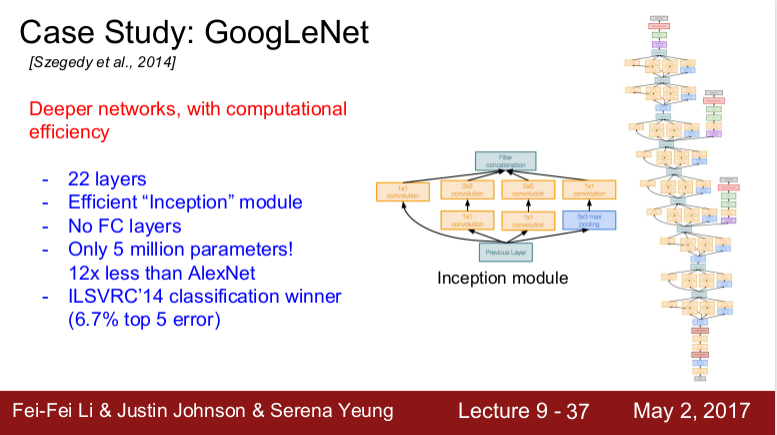
22개의 레이어를 가진다.
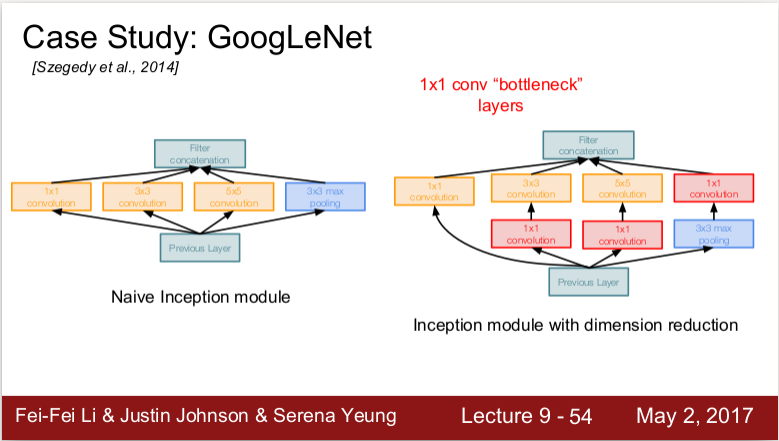
Inception module과 bottlenect layer
쉽게 말하면 이전 레이어의 입력을 받아 다양한 Conv 연산(1X1, 3X3, 5X5, pooling)을 수행하여 Depth로 합치는 방식이다.
문제는 계산 비용이다. 이들의 연산을 다 더해줄 경우 Depth가 매우 깊어지는 문제가 발생한다. 이를 줄여주기 위해서 1X1Conv를 곱해준다. (Depth가 1X1, 3X3, 5X5, pooling를 사용해주는 것보다 비선형성을 부여해주는 효과가 있기 때문인 것 같다.)
Conv layer에서는 Conv layer에 따라 Channel가 바뀌지만 pooling layer에서는 Channel가 바뀌지 않는다.
1X1 conv에서 정보손실이 발생할 수 있다. 기본적으로 사용하는 이유는 정보의 크기를 줄이기 위해서이다.
보조분류기를 중간레이어에 달아주면 추가적인 그레디언트를 얻을 수 있어 학습에 도움을 줄 수 있다.
보조분류기에서 나온 결과를 최종분류기에 사용할 수 있을까?
bottleneck layer를 구성할 때 다른 방법으로 차원으로 축소해도 되는가?
차원축소과정에서 이전의 feature map과 연관이 있는지 학습하려면 전체 네트워크를 Backprop으로 학습시킬 수 있어야 한다.
네트워크가 깊은 경우 그레디언트 신호가 작아지게 되어 0으로 수렴할 수 있다.
backprop은 한 번만 진행한다.
2016 ResNet
152 레이어를 가진다. 그렇다면 레이어의 수가 많을수록 더 좋은 것인가? 절대 아니다. 다음을 통해 확인해보자.
가설: 깊은 모델 학습 시 과적합이 될 것이다.
층이 깊어지면서 overfitting된다고 볼 수 있지만 test error와 training error가 둘 다 높으므로 (overfitting 된다면 training error는 낮아야 함) 이 때문이 아님을 알 수 있다. 오히려 층이 깊을수록 더 에러율이 높은 것을 볼 수 있다.
가설: 깊은 모델 학습 시 optimization문제가 생긴다. (모델이 깊어질수록 최적화가 어렵다)
모델이 더 깊다면 적어도 더 얕은 모델만큼은 성능이 나와야 하지 않은지라는 생각으로 추론한 방법이 Residual block을 이용한 것이다. 이 방법은 Skip-connection이라는 가중치 없이 입력을 identity mapping 그대로 출력단으로 보내는 개념을 도입하였다. 즉, 실제 레이어는 변화량만 학습하여 최종 출력값은 input X + 변화량(residual)을 내놓는 것이다.
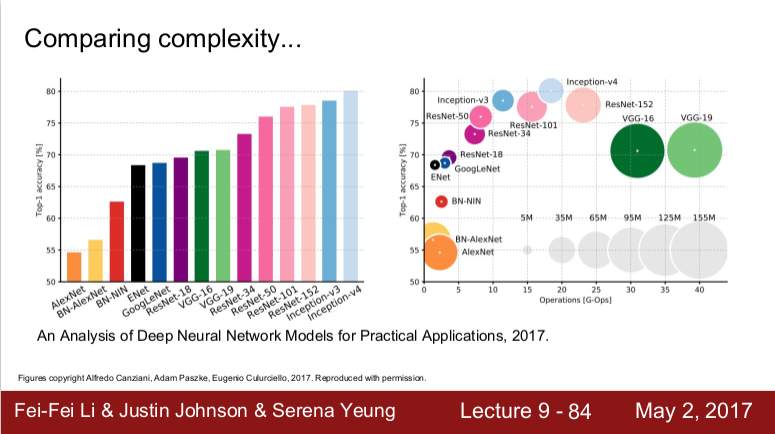
요약
(그래프에서 y축은 정확도이고, x축은 연산량이며, 원의 크기는 메모리 사용량이다.)
VGGNet은 성능은 나쁘지 않으나 메모리의 사용량이 크다.
GoogLeNet은 가장 효율적인 네트워크로 연산량과 메모리 사용량이 적다.
AlexNet은 성능이 좋지 않고 연산량은 적으나 메모리 사용량이 비효율적이다.
ResNet은 성능은 최상위이며 연산량과 메모리 사용량은 중간 정도이다.
NiN(Network in Network)

- 네트워크 안에 작은 네트워크를 넣어주는 것이 기본 아이디어이다.
- 조금 더 복잡한 계층을 만들어 activation map 을 만들자는 것이다.
- Bottle neck문제를 먼저 제기했다.
Wide Residuaal Networks

- layer를 깊이 쌓는 것보다 residual이 더 중요하다고 판단하여서 만든 것이다.
- Residual Block을 더 넓게 만들어 conv layer의 필터를 더 많이 추가하였다.
- 필터의 width를 넓히면 계산효율이 증가한다. 왜냐하면 병렬화가 더 잘되기 때문이다.
ResNeXt

- residual block의 width를 파고들어 filter의 수를 늘린 것이다.
- 각 residual block 내에 다중 병렬경로를 추가하는 것이다.
Deep Networks with Stochastic Depth

- Train time에 레이어를 짧게 하기 위해 일부 네트워크를 골라서 identity connection으로 만든다.
- Test time에서는 full deep network를 사용한다.
DenseNet

- Dense Block이란 것이 존재한다.
- Network의 입력이미지가 모든 layer의 입력으로 들어가게 되고 모든 레이어의 출력이 각 레이어의 출려과 concat된다.
- Dense connection이 vanishing gradient 문제를 완화시킬 수 있고 feature를 더 잘 전달하고 사용해줄 수 있을 것이라는 관점을 가진다.
SqueezeNet
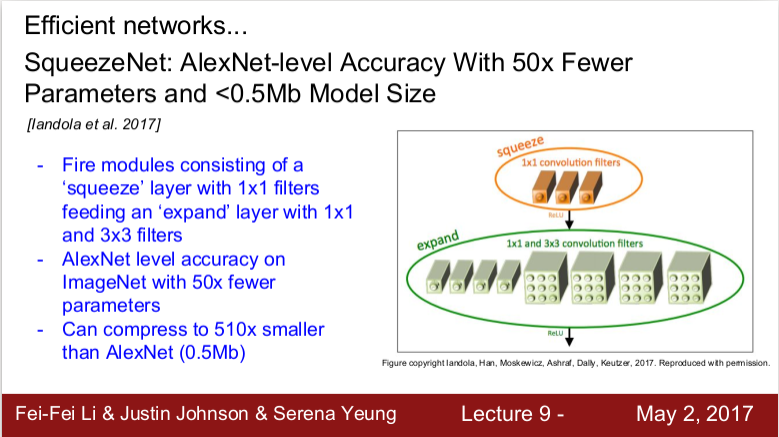
- 효율성을 강조한 모델로 squeeze layer는 1X1필터들로 구성되고 이 출력 값이 1X1/3X3 필터로 구성되는 expand layer의 입력이 된다.
- AlexNet 만큼의 효율성을 보이나 파라미터의 수는 50배 더 적다.
2021.02.21.월
2023.05.04.목 오타수정
RestNet -> ResNet
Bootle -> Bottle
-히비스서커스-
'Theory > Computer Vision' 카테고리의 다른 글
| [CS231n 11] Detection and Segmentation (0) | 2021.09.06 |
|---|---|
| [CS231n Midterm] Short Answer (12) | 2021.03.25 |
| [CS231n 7] training neural network 2 (0) | 2021.02.14 |
| [CS231n 6] Training Neural Networks 1 (0) | 2021.02.07 |
| [CS231n 5] Convolutional Neural Networks (0) | 2021.02.01 |



