
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- docker attach
- 백신후원
- logistic regression
- Decision Boundary
- Pull Request
- numpy
- HookNet
- 히비스서커스
- docker exec
- 도커
- cs231n
- CellPin
- 티스토리챌린지
- IVI
- Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images
- WSSS
- 오블완
- Jupyter notebook
- ssh
- 코크리
- docker
- 프로그래머스
- GIT
- cocre
- vscode
- aiffel exploration
- AIFFEL
- 사회조사분석사2급
- airflow
- 기초확률론
- Today
- Total
히비스서커스의 블로그
[기계학습 1강] MLE(Maximum Likelihood Estimation) 본문
※이 내용들은 (KAIST Open Online Course)의 인공지능 및 기계학습 개론 1 Chap. 1강 내용을 기반으로 재구성하였음을 먼저 밝힙니다.※
MLE (Maximum Likelihood Estimation)은 어떤 시행에 대한 확률을 고정된 값이나 알지 못하는 값으로 가정하고, 시행과 연관된 사건의 결과를 확률에 기반하여 가장 그럴듯한 값으로 추정하는 방식을 말한다. 이를 쉽게 이해하기 위해 동전던지기에 관한 예시로 살펴보자.
먼저 알아둘 것
동전을 던져 나오는 결과가 앞 또는 뒤만 나오는 것처럼 성공 혹은 실패와 같은 이분적인 결과만을 나오는 사건을 베르누이 시행이라고 한다. 이 베르누이 시행을 n번 시행하여 성공한 횟수k를 확률변수로 한 분포는 Binomial Distribution이다.
성공확률이 p인 베르누이 시행을 n번하여 성공한 횟수가 k인 Binomial Distribution의 확률질량함수는 다음과 같다.
$$ f(k; n, p) = P(K = k) = \binom{n}{k} p^{k} (1-p)^{n-k} $$
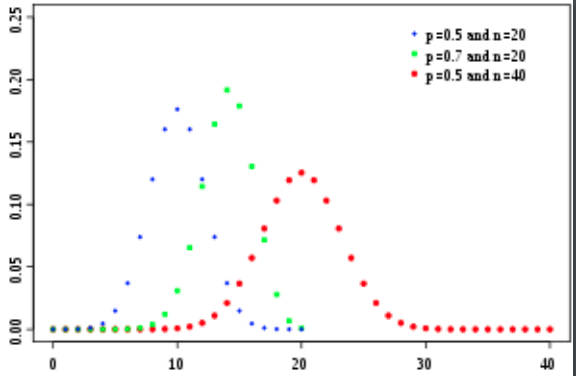
여기서 x는 k를 의미하며 y는 그 때의 확률값을 의미한다.
서론 :: HHTHT
우리는 동전을 던져 앞면이 나올 확률을 알 수 없다고 해보자.(참값 $P(H) = \theta$의 값을 정확하게 알 수 없다고 해보자.) 이때, 우리는 확률 $\theta$에 대한 점추정량 $\hat{\theta}$을 구하고 싶다. 우리는 동전을 몇 번 던져보고 그 결과를 토대로 점추정량 $\hat{\theta}$를 구할 수 있을 것이다.
동전을 5번을 던져보니 HHTHT(첫번째: 앞면, 두번째: 앞면, ... , 다섯번째: 뒷면)이 나왔다. 간단하게 표현하기 위해 사건 HHTHT를 D(Data)라고 표현을 해보자.$P(H) = \theta$, $P(T) = (1-\theta)$라 한다면, 각각의 사건은 i.i.d(identically independent distribution)의 결과이기 때문에 이 사건이 나올 확률은 $P(D) = P(HHTHT) = \theta \theta (1-\theta) \theta (1-\theta) = \theta^{3} (1-\theta)^{2}$가 된다.
본론 :: MLE
앞의 경우를 일반화 시켜보자. 앞에서 동전이 앞면 나오는 수k를 $a_{H}$로 뒷면이 나오는 수 n-k를 $a_{T}$라 하자. 또한, 동전을 n번 던져 나온 앞면과 뒷면을 순서대로 관찰한 하나의 사건을 D라 하자.
우리는 하나의 가정을 할 것인데 동전을 던져서 앞면이 나오는 사건은 성공확률이 $\theta$인 Binomial Distribution을 따른다고 할 것이다. 그러면, 확률 $\theta$가 주어졌을 때 사건 D가 나올 확률은 다음과 같이 $\theta$에 대한 함수로 표현된다.
$$ P(D|\theta) = \theta^{a_{H}}(1-\theta)^{a_{T}}$$
지금의 상황을 다시 설명해보자면, 확률 $P(H) = \theta$에 대한 정확한 값을 모르고 있기 때문에 이에 대한 점추정량 $\hat{\theta}$은 수 없이 많다. 하지만, 일단 $\theta$가 정해지기만 하면 그때의 사건이 나올 확률은 $ P(D|\theta) = \theta^{a_{H}}(1-\theta)^{a_{T}}$가 된다. 앞서 $\theta$가 정해지지 않았으므로 $\theta$에 대한 함수로 나타낼 수 있는데 여기서 $ P(D|\theta)$가 최대가 되게 하는 $\theta$의 점추정량 $\hat{\theta}$을 구할 수 있다.
이를 식으로 표현해보자면
$$\hat{\theta} = argmax_{\theta} P(D|\theta) = argmax_{\theta} \theta^{a_{H}} (1-\theta)^{a_{T}}$$
argmax란, argument of max란 뜻으로 어떤 함수 (여기서는 $P(D|\theta)$)를 최대로 만드는 정의역의 매개변수(여기서는 $\theta$)를 말한다.
이를 구하기 위해서는 미분을 해주어야 하는데 여간 쉬운 것이 아니다. 이를 위해서 한 가지 트릭을 써보자면 증가함수인 log를 취해준 후 미분을 해주는 것이다. 그래도 $argmax_{\theta} P(D|\theta)$의 값은 동일하다.

MLE($P(D | \theta)$)는 이처럼 동전이 앞면 나올 확률$P(\theta)$을 고정된 값(= 분포를 따르지 않는 상수의 값)이나 알지 못하는 값으로 가정하고 동전을 던져 나온 결과들을 토대로 가장 그럴듯한(= 가장 높은 가능도를 가지는) 값으로 추정하는 방식이라고 이해하면 쉽다.
결론 :: $\hat{\theta}$은 $\frac{a_{H}}{a_{H}+a_{T}}$
결론적으로 $\theta$에 대한 점추정량 $\hat{\theta}$은 $\frac{a_{H}}{a_{H}+a_{T}}$이 된다. 그렇다면 동전을 5번 던져서 앞면이 3번 나왔을 때와 50번 던져 30번 나왔을 때는 $\frac{3}{3+2} = \frac{30}{30+20}$이므로 차이가 없는 것일까?
50번 던져 30번 나왔을 때의 사건에서는 5번 던져서 앞면이 3번 나왔을 때보다 에러가 줄어든다. 이는 아래의 Hoeffding's inequality식을 통해 알 수 있다.
$$P(|\bar{\theta} - \theta^{*}|\geq \varepsilon) \leq 2e^{-2Ne^{2}}$$
여기서, $\hat{\theta}$는 $\theta$에 대한 점추정량, $\theta^{*}$는 참값, $\varepsilon$은 최소한으로 허용하는 오차(추정량과 참값의 차이), e는 error bound, N은 시행횟수이다.
즉, 시행횟수 N이 커질수록 오른쪽 식의 값이 작아지고, 추정량과 참값의 차이가 $\varepsilon$ 값의 범위보다 커질 확률을 줄여준다! 이것은 PAC(Probability Approximate Correct) learning의 한 예라고 할 수 있다.
-히비스서커스-
'Theory > Machine Learning' 카테고리의 다른 글
| [기계학습 3강] Optimal Classification (0) | 2021.04.06 |
|---|---|
| [기계학습 2강] Linear Regression (0) | 2021.04.05 |
| [기계학습 2강] Decision Tree & Information Gain (0) | 2021.04.02 |
| [기계학습 2강] Rule Based Machine Learning (0) | 2021.03.31 |
| [기계학습 1강] MAP(Maximum A Posterior) (0) | 2021.03.29 |



