
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- cs231n
- vscode
- 코크리
- docker exec
- 도커
- 프로그래머스
- 백신후원
- 기초확률론
- Jupyter notebook
- Pull Request
- airflow
- 티스토리챌린지
- AIFFEL
- IVI
- 사회조사분석사2급
- aiffel exploration
- Decision Boundary
- logistic regression
- Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images
- numpy
- WSSS
- docker attach
- 히비스서커스
- ssh
- cocre
- GIT
- 오블완
- docker
- CellPin
- HookNet
- Today
- Total
히비스서커스의 블로그
[Paper] Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images 논문 번역 본문
[Paper] Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images 논문 번역
HibisCircus 2021. 12. 3. 16:34Gu, F., Burlutskiy, N., Andersson, M., Wiln, L.K., 2018. Multi-resolution Networks for Semantic Segmentation in Whole Slide Images의 논문을 읽고 제가 직접 번역해본 글입니다. 틀린 부분이 있다면 지적해주세요.
Abstract
digital pathology는 WSI의 semantic segmentation과 같은 업무 수행을 위해 FCN를 적용하는데 아주 좋은 기회를 제공한다. 하지만 표준 FCN은 WSI의 재배열에 관한 pyramid의 구조로부터 상속받은 multi-resolution의 관점에서 어려움을 맞이한다. 결과적으로 다른 level에 정보를 집약하고 배우도록 설계된 특별한 network가 요구된다. 이 논문에서는 WSI에서 binary semantic segmentation의 표준데이터로 검정되는 가장 인기있는 Unet을 기반으로 한 multi resolution network를 제안한다. 제공된 방법은 우수한 학습과 일반화 능력을 갖는 Unet을 능가한다.
1. Introduction
병리전문의들의 일하는 패턴은 조직의 등급을 메기기 위해 움직이며 zoom-in과 zoom-out을 반복하는 것으로 빈번히 묘사된다. 이 행동은 현미경이 사용하거나 WSI를 스크린을 통해 관찰될 때나 비슷할 것이다. 사람의 시각 시스템은 조직의 등급을 메기기 위해 이러한 다양한 관점을 필요로 한다. 주변 환경과 독립적으로 슬라이드의 국소적 주변을 안전하게 등급을 메기는 경우는 드물다. 복잡한 3D 구조에서 잘라낸 2D의 재현물만 슬라이드에 나타나는 것이 문제의 핵심이다. 3D glandular tiissue는 cauliflower의 구조와 닮았다. 잘라낸 2D의 위치에 의존하여 슬라이드 위의 gland의 사이즈와 모양은 두드러지게 다양할 것이다. 모양과 크기의 편차의 원인이 자른 위치 때문이거나 병변 때문인지 평가하기 위해서 다중의 해상도 시각은 중요하다. 현재 gland가 높은 해상도에서 분석되어 질 때 gland를 둘러싼 구조는 할당되어야 한다.
디지털 병리학은 WSI의 semantic segmentation을 위한 FCN(Fully Convolutional networks)를 사용함으로써 병리전문의들을 도울 수 있는 가능성을 열어주었다. 표준 FCN도 하지만 multi-resolution이라는 관점에서 같은 어려움을 직면하였다. U-net과 같은 네트워크가 내제된 구조와 같은 이유 때문에 다중 해상도를 어느 정도 다룰 수 있다고 제기되었다. 하지만 수용성과 같은 것을 사용하기 위해서 가장 세부적인 정보를 갖는 patch들은 가장 높은 해상도에서 추출되었을 것이다. patch의 크기를 키우는 것 또한 필요한데 이는 다중 해상도를 완전하게 탐험하기 위해 최신의 GPU의 VRAM를 통해 실현가능하다. 결과적으로 다중 해상도에서 효율적이고 효과적인 정보를 추출해내고 데이터로부터 학습할 수 있는 접근이 요구된다.
이 논문에서 다중 해상도의 네트워크는 다중 level에서 추출된 패치로부터 학습할 수 있도록 제기되었다. 이러한 패치들은 같은 중심점을 공유하고 모양도 동일하지만 픽셀의 크기(mpp)의 증가를 기반으로 한 octave를 함께 한다. 고해상도 패치의 중심만이 결과로 segmented 되어 나온다. 제기된 방법은 WSI의 벤치마크 데이터에서 표준 U-Net과 비교하고 평가되었다.
2. Related work
semantic segmentation문제들은 초기에 손으로 얻어진 특징들을 처리하는 전통적인 머신러닝 기법들의 접근 방법으로 해결되었다. 연구자들은 조직병리학적 조직의 특징을 추출하기 위해 공간적 피라미드와 매칭하고 predictive sparse decomposition과 같은 방법들을 적용하였다. 하지만 FCN을 기반으로 한 딥러닝 기법이 더 높은 성능을 뚜렷하게 보여줌으로써 마침내 대체되었다. 소위 '서양의 장기판 유물'이라 불리는 transposed convolution을 극복하기 위해 dilated convolutions을 이용한 upscaling과 DeepLab-CRF, SegNet 등과 같은 여러 접근들이 제기되었다. 특징들로부터 학습된 정보를 증가시키기 위해 downsampling path로부터의 높은 해상도 특징들은 upsampled되는 결과물과 결합될 수 있다. 이러한 과정은 'skip connetcions'이라 알려져 있고 이는 결합된 정보를 기반으로 한 정확한 결과와 같아지고 학습하도록 성공적인 convolution layer를 가능하게 하였다. 연구자들은 skip connection을 가진 구조가 더 좋은 성과를 가진다는 것을 성공적으로 증명해냈다. 이러한 네트워크는 skip connection을 가지는 highway 네트워크와 densely connected convolutaional network와 Unet등을 포함한다. 전반적으로 Unet은 biomedical segmentation 업무를 위한 가장 인기있는 네트워크 중 하나로 증명되었다.
표준 FCN의 제한점으로는 같은 receptive field 사이즈를 가지는 filter들의 모음을 지닌 convolution layer으로 구성된다는 것이다. receptive field 사이즈는 그 네트워크가 학습할 수 있는 context와 상응하고, 궁극적으로 network의 성능에 영향을 미친다. Grais et al.에서 오디오 소스 분류 문제를 위한 각각의 레이어에 대한 다른 receptive field 크기를 가진 다중 해상도 FCN을 제기하였다. 이러한 설계는 다수의 관점에서의 같은 입력값의 특징을 추출하도록 허용하여 입력값으로부터 세부적이고 전체적인 정보를 추출하도록 한다. Fu et al.은 다른 입력의 모양과 스케일의 같은 이미지 내용은 네트워크를 통해 통과하는 곳에서 optic disc와 optic cup segmentation의 병합의 문제에 달려들기 위해 Multi-scale Mnet을 도입하였다. 하지만, 두 방법은 의미있는 변화를 가진 filed를 encoder에 적용하거나 다중 스케일과 함께 입력을 가짐으로써 같은 입력의 오디오와 이미지의 내용을 다루도록 고안되었다. Roullier et al. 은 mitotic cell segmentation을 위한 WSI의 다중 해상도 graph-based 분석을 제안하였다. 이 접근은 다른 도메인 문제에 쉽게 적용되지 못하는 특정 도메인을 기반으로한다. 최근, FNC 안에서 다중 해상도 정보를 이용한 접근이 묘사되었다. 하지만, 다중해상도 입력의 융합은 네트워크 사이에서가 아닌 encoder 이전에 수행되었다. 게다가, 이러한 접근은 WSI 보다는 관심있는 작은 영역의 하위 집합에만 적용된다.
WSI 안에서 같은 조직 부위와 상응하는 것에 관하여 다른 해상도로부터 추출된 입력을 통합하는 네트워크가 다중 해상도 문제에 달려들기 위해 필요하였다. 게다가 네트워크는 해상도의 관점에서 확장가능해야 했고, VRAM은 훈련과 예측을 위해 효율적이었다. 이것이 이번 작업에서 다중 해상도 네트워크를 개발하게 된 원동력이다.
3. Algorithmic Formulation
딥러닝으로 WSI를 다루는 것에서 가장 흔한 관행은 다수의 동일한 크기의 패치로 나누는 것이다. 여기서 딥러닝 작업은 각각의 패치들이 하나의 이미지 예시로 간주되는 곳에서 패치들의 binary semantic segmentation 문제로서 공식화된다. 예측에서 훈련 모델은 첫째로 개별 패치들을 각각 예측하고, 모든 패치들의 이은 후 전체 슬라이드를 예측하도록 한다.
3.1 Learning and Inference
$(x,y) \in X*Y$. 패치나 주어진 데이터를 이와 같이 두자. $X \subseteq \mathbb{R}^{N*D*3}$이고 $Y \subseteq \mathbb{N}^{N*D}$이다. 여기서, $N$은 패치의 수, $D$는 패치의 $w$(가로의 길이)와 $h$(세로의 길이)의 곱이다. 따라서, $x$는 슬라이드로부터 추출한 RGB 이미지이고, $y$는 슬라이드에 대한 binary ground truth mask이다. 우리는 $f(x; W)$와 딥러닝 식으로 구할 수 있다. $W$는 모든 레이어에서의 파라미터에 대한 가중치이다. 학습의 과정은 loss function (= $L(y, f(x_i; W)) + \lambda R(W)$)을 최소로 하는 파라미터인 $W$를 찾아가는 과정이다. 결과값은 sigmoid function을 거쳐서 0과 1 사이의 확률값을 가지도록 변형된다. loss function으로 흔히 binary cross entropy loss를 사용한다. 오버피팅을 방지하고 훈련 모델의 일반화 수용성을 높이기 위해 regularization term인 $R(\cdot)$을 추가하여 다음과 같이 $\varepsilon_w = \sum_{N}^{i=1} L(y, f(x_i; W)) + \lambda R(W)$ 나타낼 수 있다. 여기서 $\lambda$는 두 텀의 영향력을 결정해주는 스칼라 값이다. 인기 있는 regularization function 중 하나는 $R(W) = \left \| W \right \|^2 _2$과 같은 $l_2$regularization이다. $\varepsilon_w$을 최소로 하는 $W$의 값을 찾는 것이 딥러닝 에서 최적화 과정으로 알려져 있다. 인기 있는 최적화 방법은 SGD, AdaGrad, RMSProp등이 있다. 최근 Adam이 딥러닝 최적화 과정에서 가장 인기 있는 방법이다.
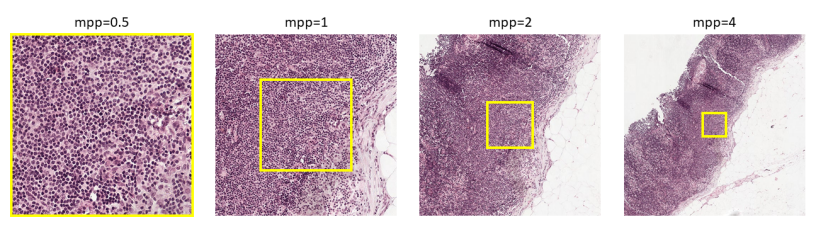
왼쪽에서 오른쪽까지 패치는 중심점이 동일하되 mpp가 증가하고 배율은 감소하는 이미지들이다. (가장 왼쪽 이미지의 mpp가 0.5이고 배율이 20X이다.) mpp가 증가하여 줌 아웃이 됨에 따라 yellow squares는 다른 배율에서 나타내는 부분이 달라짐이 보여진다.
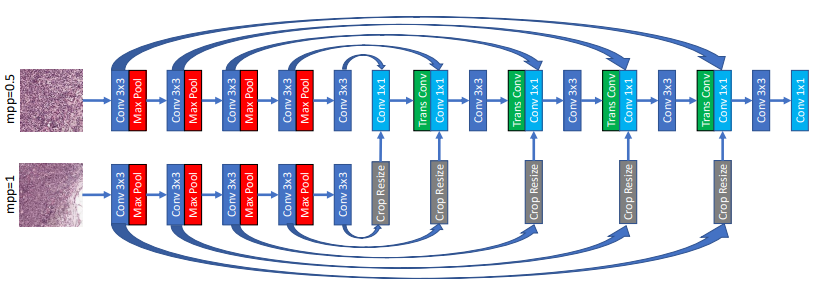
MRN 방법을 일러스트화 한 것이다. Conv 3x3은 3x3 convolution layer와 ReLU activation이 합친 것을 나타내고, MaxPool은 2x2 max pooling layer를 나타낸다. Conv 1x1은 1x1 convolution layer와 identity activation이 합친 것을 나타내고 TransConv는 stride값이 2인 2x2 transposed convolution layer와 ReLU activation를 합친 것을 나타낸다.
3.2 Multi-Resolution Networks
Unet을 근거한 두 개의 multi-resolution networks(MRN)을 제시한다. 표준 Unet은 downsampling과정을 진행하는 encoder와 upsampling 과정을 진행하는 decoder의 2 부분으로 나뉜다. downsampled되는 feature map은 이에 상응하는 upsampling path에 concatenated 된다. 제기된 MRN은 다른 해상도(구조적으로 동일한 downsampling을 가지고, 디코더 하나는 upsampling)에 상응하는 다중 encodner를 적용한다.
Fig 1에 나와있듯이 모든 해상도의 입력 모양은 동일하고 동일한 중점을 공유하고 있으며 파리미드 방식으로 조직 영역을 효과적으로 나타낼 수 있다. 해상도가 순서대로 줄어드는 $x_j = [x_1, x_2, ... , x_J]$와 $y = y_1$조건에서의 $(x,y)$ 예시로 들자. $x$와$y$의 모양은 각각 $h*w*3*J$와 $h*w*1$일 것이다. 이와 같은 배열의 근거는 픽셀의 일치도가 표준 Unet과 비교하여 더욱 성가시기 때문이다. 핵심은 네트워크의 저해상도 branch가 주변 영역에서 중앙부분으로 정보를 성공적으로 전달할 수 있도록 충분한 receptive field를 활성화하는 것이다.
저해상도의 관심영역과 상대적인 정보를 보전하기 위해 우리는 각각의 encoder unit의 feature map의 결과를 center crop하였고 upscaling을 통하여 resize한 후 원래의 resolution으로 되돌렸다. 우리는 nested function을 cropping factor가 $\gamma = 2^\mathbb{N}$를 만족할 때(2의 배수로 나오게 되는 것은 downsampling을 거치며 $h, w$가 2배 씩 달라지기 때문), $u \circ v$와 같이 나타내었다. 한편으로 function $u$가 center crop되어 $h*w*c$가 $\frac{w}{\gamma} * \frac{h}{\gamma} *c$와 같은 텐서가 된다. 다른 편으로, $v$는 $u$로 upscaling되며 원래의 모양의 결과를 내게 된다. upscaling에서 우리는 bilinear interpolation(보간법)을 사용한 'MRN-bilinear'와 transposed convoltuion을 사용한 'MRN-transposed' 두 가지의 옵션을 주었다.
$u \circ v$의 결과는 높은 해상도를 가지는 encoder에서 상응하는 layer의 convoluted feature map에서 concatenated 된다. 그런 후 concatenated feature map은 decode 레이어의 합쳐지기 전에 1x1 convolution layer와 동일한 identity activation을 거치게 된다. 1x1 convolution은 해상도의 수가 포함됨에도 불구하고 decoder 상수 안의 feature map의 수를 유지하는 동안 모든 해상도로부터의 feature map을 모아 가중 합한 것과 같은 역할을 한다. Fig.2는 두 해상도가 포함된 네트워크의 예시이고 많은 해상도에도 쉽게 설명될 것이다.
4. Experimental Conditions
4.1 Implementation Details
우리는 Tensorflow 프레임워크에서 same padding을 적용하여 수행하였다. 모든 convolution과 transposed convolution layer에 수렴율 높이고 오버피팅을 피하기 위해 $\lambda$ = 0.005인 bacth normalization과 $l_2$-regularization을 사용하였다. 우리는 Adam optimizer의 디폴트 값을 적용하였다. 입력 모양은 가로, 세로 모두 512이고 mpp는 동시에 모든 해상도가 MRN과 Unet에 다뤄지는 조건에서 {0.5, 1, 2, 4}의 범위 안에서 하였다. batch size는 NVIDIA Titan XP의 VRAM에 의해 제한되는 16으로 동일하다. 훈련의 최대 epoch는 500으로 하였다.
4.2 Segmentation Experiments
CAMELYON datasets은 pixel-level annotation이 된 사용가능한 공개 WSI dataset이다. 특히, digital pathology분야에서 가장 인기 있는 benchmark 데이터 중 하나로 training과 testing 세트로 이용가능하다. 결과적으로, WSI에서 normal class와 tumor class의 binary semantic segmentation을 위해 표준 Unet의 대응하는 방법으로 제기되어 검증을 위해 사용된다. training set에는 269개의 슬라이드를 가지는데 159개는 normal slide이고, 110개는 tumor slide이다. Deep Learning for Identifying Metastatic Breast Cancer (2016)에서 언급하였듯, 18개의 슬라이드는 포괄적이지 않은 annotation을 가지고 있어 실험에서 제외되었다. training set는 랜덤하게 나뉘어 80%는 training을 위해 20%는 validation을 위해 나뉘었고, validation set은 validation loss가 가장 낮게 하는 모델을 best model로 선정하는데 사용되었다. Testing set은 130개의 슬라이드를 가지며 80개는 normal이며 50개는 tumor이다. 2개의 슬라이드가 포괄적이지 않아 실험에서 제외되었다.
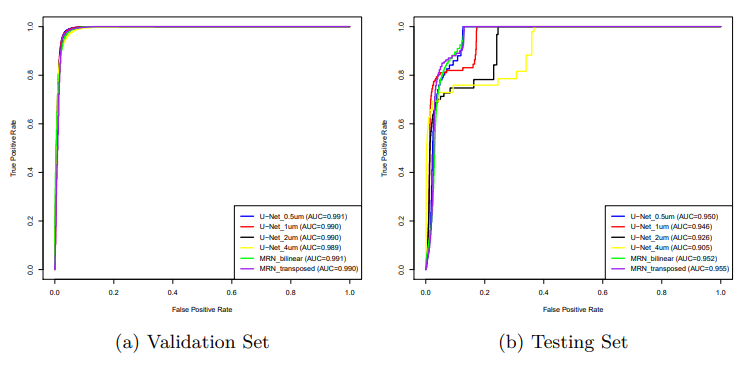
CAMELYON16 데이터에 대해 표준 Unet과 MRNs의 비교가 다른 threshold가 예측을 위해 적용되었다.
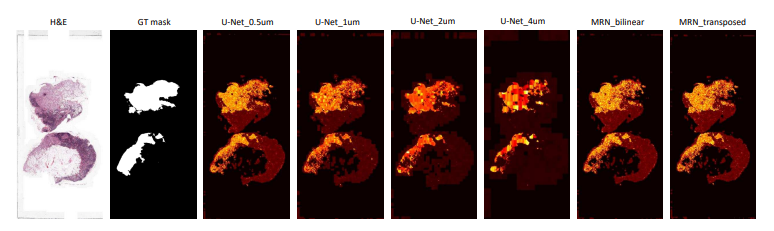
'test_090' slide에 모든 방법들에 대해 정성적인 비교
5. Results and Analysis
이번 절에서 우리는 정량적인 관점과 정성적인 관점 모두로부터의 방법을 비교하였다. 정량적으로 우리는 training data로부터 학습하는 능력과 이 보다 더 중요하게 한번도 보지 않은 testing set에 대해 일반화된 수용성을 갖는 것으로 평가하려는 의도를 가진다. 따라서, 우리는 Fig.3에 보여진 ROC에 나와 있듯 validation set과 testing set 둘 다를 평가하였다. validation set에서 결과는 다소 동일하나 MRN-transposed가 약간 더 좋았다. 이는 주어진 데이터로부터 모든 방법은 학습이 가능한 것임을 알 수 있다. testing set의 결과는 상당히 다르다. 첫번째로 표준 Unet의 성과는 mpp값이 증가하므로 감소한 반면 제안된 네트워크는 U-Net의 변종들에 대해 더 월등한 성과를 내었다. MRN-Transposed의 성과가 더 좋을 수 있었던 이유는 MRN-bilinear보다 더 높은 수용성을 가지기 때문인데 이는 transposed convolutions은 파라미터를 가지고 bilinear interpolation은 가지지 않기 때문이다.
정성적인 결과의 이해를 돕기 위해서, 우리는 Fig.4에 보여진 것과 같이 훈련된 모델로 예측하여 mask 처리된 H&E slide를 plot처리 하였다. mpp값이 올라감에 따라, U-net의 변형들의 예측값은 더 희박해지고 덜 예측을 하였다. 하지만 MRN-bilinear와 MRN-transposed의 예측값은 충분한 양의 세부사항을 포함하였고 상대적으로 예측을 더 많이 하였다. 이는 왜 두 모델들이 pixel 수준의 평가에서 가장 좋은 성능을 보여주는지 설명해준다.
6. Conclusions and Future Work
이 논문에서 우리는 WSI의 다른 해상도로 추론하고 배우도록 2개의 해상도를 갖는 네트워크를 제안했다. binary semantic segmentation을 위한 표준 Unet에서 표준데이터에 대하여 SOTA의 결과와 월등한 성과를 보였다. 이 결과들은 모델들의 우월한 학습력과 일반화 수용성을 증명한다. 게다가, 제안된 방법은 메모리 효율적인데 이는 다른 해상도의 입력 모양의 일정함이 훈련과 예측에서 VRAM linear한 증가를 만들기 때문이다. 더욱이, 우리는 각각 한 모델을 학습하는 것 대신 그 해상도를 가지는 모델을 단 하나로 훈련할 수 있다.
나중의 일로, 우리는 multi-class semantic segmentation과 같은 더욱 어려운 문제들에 대한 방법들을 적용할 것이다. 이번 일에서 제안도니 같은 원리를 적용하여 multi-resolution이 가능하도록 네트워크 모양을 바꿀 수 있을 것이다. 더욱이 우리는 더욱 높은 수용성을 갖는 방법을 개발하도록 semantic segmentation network의 block을 설계하도록 실험할 것이다.
-히비스서커스-



