
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 오블완
- 기초확률론
- airflow
- 코크리
- 사회조사분석사2급
- ssh
- docker exec
- WSSS
- IVI
- 티스토리챌린지
- cs231n
- Jupyter notebook
- vscode
- docker
- logistic regression
- 도커
- AIFFEL
- Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images
- 백신후원
- cocre
- 프로그래머스
- 히비스서커스
- GIT
- HookNet
- CellPin
- Pull Request
- docker attach
- numpy
- aiffel exploration
- Decision Boundary
- Today
- Total
히비스서커스의 블로그
[Paper] Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images 논문 정리 본문
[Paper] Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images 논문 정리
HibisCircus 2021. 12. 6. 17:27※ Gu, F., Burlutskiy, N., Andersson, M., Wiln, L.K., 2018. Multi-resolution Networks for Semantic Segmentation in Whole Slide Images의 논문을 읽고 제가 직접 이해한대로 정리해본 글입니다. 틀린 부분이 있다면 지적해주세요.
핵심 요약
MRN은 WSI의 다른 level에서 정보를 집약하고 배우도록 설계된 Unet 기반의 모델이다.
1. 등장배경
multi-resolution의 필요성
조직의 등급을 메기기 위해서는 zoom-in하여 세밀한 부분을 보는 관점과 zoom-out하여 전체적인 부분을 보는 관점이 모두 필요하다. 이는 복잡한 정보를 가지는 3차원인 조직의 단면을 단순히 잘라낸 2차원에서 gland의 사이즈와 모양이 다양하게 되는 것과 관련이 있다. 슬라이드에 나타난 것이 이러한 원인 때문인지 병변 때문인지 알기 위해서는 주변 정보를 가져오기 위해서는 multi-resolution 관점이 매우 중요하다.
기존 모델들의 한계
디지털병리학의 길을 열어준 FCN은 multi-resolution의 문제를 맞이하였고, 가장 사랑받는 Unet 또한 multi-resolution을 위한 어느 정도 다룰 수 있으나 큰 해상도 차이를 가지지 못한다. GPU의 사용을 효율적으로 하며 고해상도와 저해상도 정보를 둘 다 가질 수 있는 효과적인 방법이 필요하다.
2. 관련 연구
전통적인 연구방법
- 직접 특징들을 추출하여 머신러닝 기법으로 처리하였음- spatial pyramid matching

자세한 내용은 이곳을 참조
- predictive sparse decomposition
predictive sparse decomposition은 데이터의 희소 표현을 학습하는 비지도 학습 방법이다. 식은 아래와 같으며

도식화한 그림은 아래와 같다.

자세한 내용은 이곳을 참조
skip-connections
- downsampling path를 거친 후 upsampling path로 거치며 특징들을 더해주기 위한 결합과정
- 정확한 결과와 같아지고 성공적인 convolution 학습이 가능하게 됨
- 최대 아웃풋은 Unet임
다른 multi-scale 방법론적 시도들
- Grais et al. Audio source classification problem

각각의 레이어에 대한 다른 receptive field 크기를 가진 다중 해상도 FCN를 제기하였다.
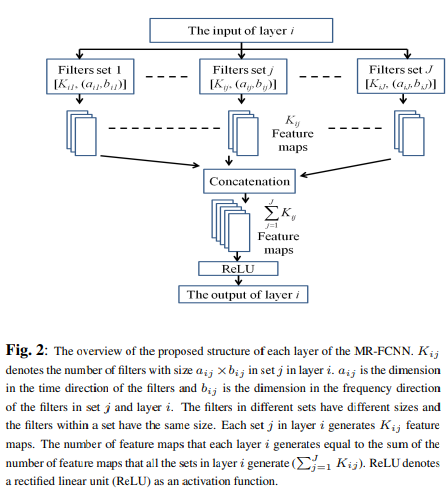
- 다수의 관점에서의 같은 입력값의 특징을 추출하도록 함
- 세부적이고 전체적인 정보를 추출하도록 함
- Fu et al. Multi-scale Mnet
optic disc와 optic cup
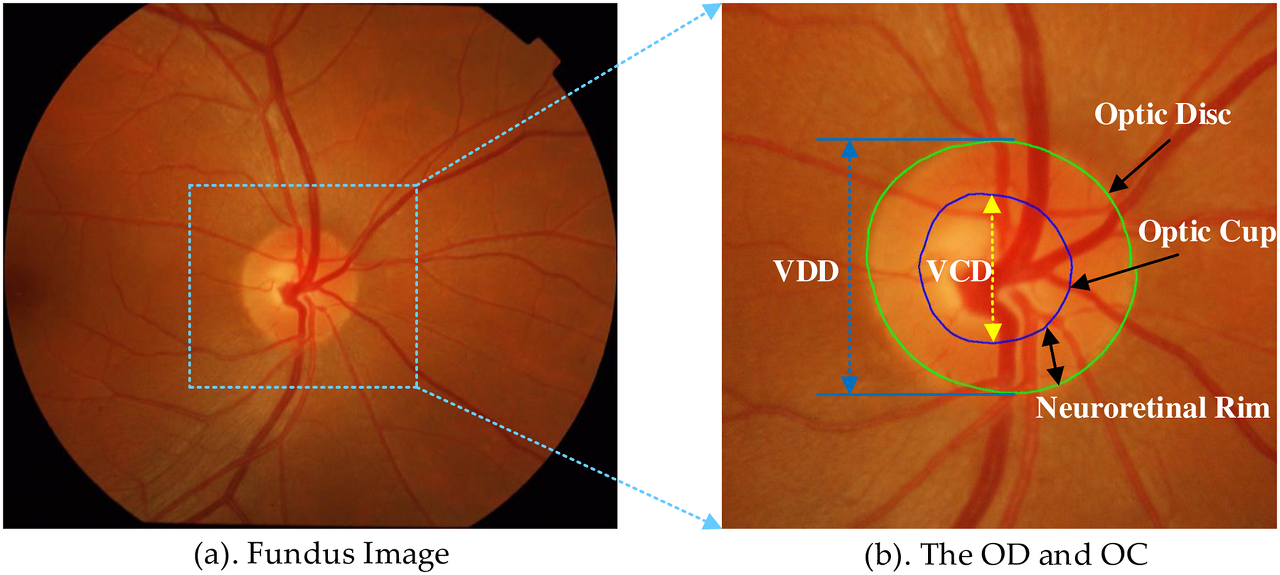
- 다른 입력의 모양과 스케일의 같은 이미지 내용을 구성
- 네트워크를 통해 통과하는 곳에서 optic disc와 optic cup의 segmentation의 병합문제를 위해 Multi-scale Mnet을 도입하였다.
3. 알고리즘 공식
다수의 동일한 크기의 패치로 나누기
- 딥러닝으로 WSI를 다룰 시 가장 많이 하는 방법
- 개별 패치들을 학습한 후 개별 패치들의 예측값들을 모아 전체 슬라이드를 예측함
3-1. 학습 및 추론
$(x,y) \in X*Y$
- $X \subseteq \mathbb{R}^{N*D*3}$, $Y \subseteq \mathbb{N}^{N*D}$
- $N$은 패치의 수, $D$는 패치의 $w$(가로의 길이)와 $h$(세로의 길이)의 곱
- $x$는 슬라이드로부터 추출한 RGB 이미지, $y$는 슬라이드에 대한 binary ground truth mask
$\varepsilon_w = \sum_{N}^{i=1} L(y, f(x_i; W)) + \lambda R(W)$
- $f(x; W)$은 딥러닝 식, $W$는 모든 레이어에서의 파라미터에 대한 가중치
- 학습과정 :: loss function (= $L(y, f(x_i; W)) + \lambda R(W)$)을 최소로 하는 파라미터인 $W$를 찾아가는 과정
- 결과값 :: sigmoid function을 거쳐서 0과 1 사이의 확률값을 가지도록 변형
- loss function :: binary cross entropy loss를 사용
- regularization term :: $R(\cdot)$, 오버피팅을 방지하고 훈련 모델의 일반화 수용성을 높이기 위해 사용
- 최적화 과정 :: SGD, AdaGrad, RMSProp, Adam
3-2. 다중해상도 네트워크
표준 Unet의 구조
- downsampling 과정을 진행하는 encoder + upsampling 과정을 진행하는 decoder
- skip-connection : downsample 되는 feature map에 상응하는 upsampling path에 concatenate함
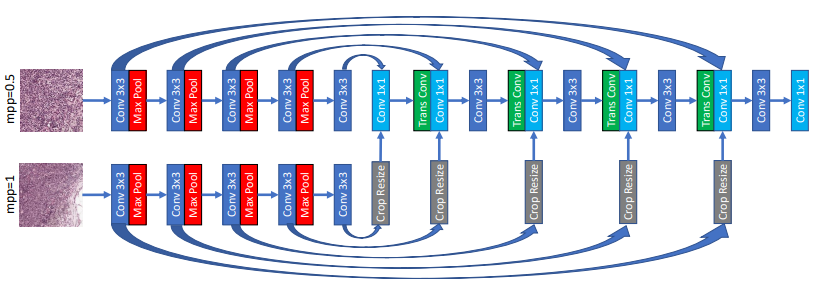
적용한 MRN
- mpp가 다른 입력을 받는 동일한 구조의 2개의 decoder + 작은 mpp에 대한 한 개의 encoder
- 이는 작은 mpp를 입력으로 받는 Unet과 큰 mpp를 입력으로 받는 decoder로 구성되어 있다고도 볼 수 있음
- 작은 mpp를 입력으로 받는 Unet에 큰 mpp를 입력으로 받는 decoder에서의 skip-connections을 받게 됨
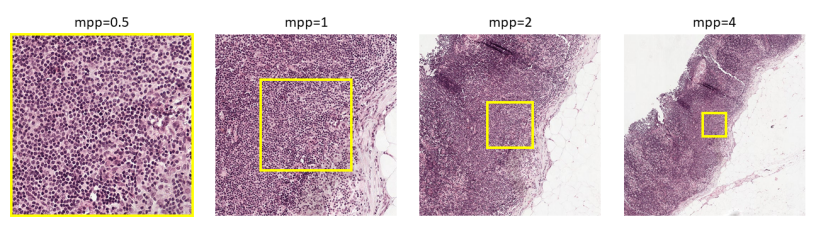
- 이때 다른 mpp를 갖기 때문에 작은 mpp의 입력으로 받는 이미지가 나타내는 부분이 큰 mpp를 갖는 부분의 일부분이 됨 (Fig. 1을 참조)
- 이를 맞춰주기 위해 crop을 해주고 이때 크기가 달라지기 때문에 resize를 해주어 크기를 맞춰준다음 skip-connection을 하는 것임
upsampling 시 다른 조건
- MRN-bilinear : bilinear interpolation을 이용한 방법
- MRN-transposed : transposed convolution을 이용한 방법
4. 실험 조건
4-1. 실행 세부사항
- Tensorflow Framework
- $\lambda$ = 0.005인 bacth normalization과 $l_2$-regularization을 사용
- Adam optimizer 자세한 세팅은 디폴트 값
- mpp : 0.5, 1, 2, 4
- input shape : 512 X 512
- batch size : 16
- epoch : max 500
4-2. segmentation 실험
- CAMELYON datasets
- training set total 269개( =159개 normal slide + 110개 tumor slide) 이 중 18개 제외 + train, validation 8:2의 비율
- test set total 130개 (= 80개 normal slide + 50개 tumor slide) 이중 2개 제외
5. 결과 분석
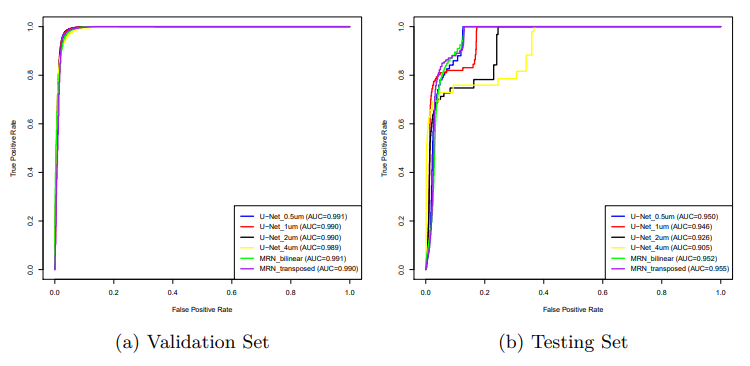
validation set 결과
- 다소 동일하나 MRN-transposed가 약간 더 좋음
- 주어진 데이터로부터 모든 방법은 학습이 가능한 것임을 알 수 있음
test set 결과
- 표준 Unet의 성과는 mpp값이 증가하므로 감소
- 제안된 네트워크는 U-Net의 변종들에 대해 더 월등한 성과
MRN transpose가 MRN-bilinear보다 월등한 이유
- transposed convolutions은 파라미터를 가지고 bilinear interpolation은 가지지 않기 때문
참고
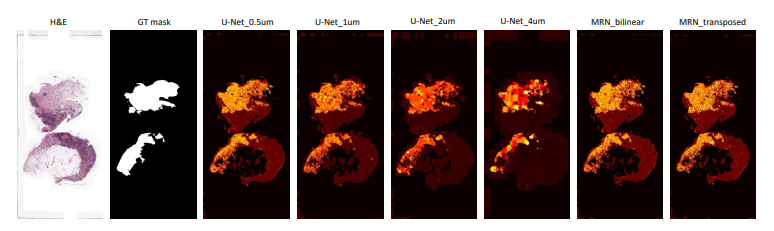
정성적 결과분석
- Unet 계열 : mpp값이 올라감에 따라, U-net의 변형들의 예측값은 더 희박해지고 덜 예측
- MRN 계열 : 충분한 양의 세부사항을 포함하였고 상대적으로 예측을 더 많이 함
6. 결론 및 추가적으로 해볼만한 사항
- MRN이 Unet보다 월등한 성과를 보임
- multi-class segmentation에 대해 진행해보면 좋을 것
+ 구현
https://github.com/gotjd709/MRN
GitHub - gotjd709/MRN
Contribute to gotjd709/MRN development by creating an account on GitHub.
github.com
- 히비스서커스 -



