
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- docker attach
- Jupyter notebook
- airflow
- aiffel exploration
- 백신후원
- 오블완
- GIT
- docker
- vscode
- 프로그래머스
- 티스토리챌린지
- logistic regression
- 기초확률론
- IVI
- docker exec
- 히비스서커스
- WSSS
- HookNet
- numpy
- Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images
- cocre
- cs231n
- Pull Request
- AIFFEL
- 사회조사분석사2급
- CellPin
- ssh
- Decision Boundary
- 코크리
- 도커
- Today
- Total
히비스서커스의 블로그
[WSSS] CIAN 논문 정리 본문
※ CIAN: Cross-Image Affinity Net for Weakly Supervised Semantic Segmentation의 논문을 읽고 이해한대로 정리해본 글입니다. CIAN 논문은 풀잎스쿨 18기 WSSS 논문으로 입문하기에서 제가 발표를 맡았던 논문으로 아래에 첨부된 그림들 중 논문에 나와있지 않은 그림들은 제가 제작한 내용이니 사용 시 반드시 출처를 남겨주시기 바랍니다. 풀잎스쿨 18기 WSSS 논문으로 입문하기를 통해 같이 공부한 분들께 감사를 드립니다.
개인적인 생각
많은 WSSS의 방법들이 존재하였지만 한 이미지 안에서 클래스의 영역들을 어떻게 더 정확한 위치에서 정교하게 segmentation을 할 것인가에 대한 방법들이 많았다. 데이터셋 안에 있는 이미지 안에서 클래스들의 유사도가 있을터인데 이를 적용하고자 한 논문이 CIAN이다. 방법에 대한 아이디어도 매우 뛰어나지만 이 방법이 WSSS의 성능과 독립적이으로 작용하여 성능에 영향을 주지 않음을 실험적으로 밝혔는데 실험설계와 결과분석이 눈여겨볼만 하다. 아이디어 뿐 아니라 방법론까지 살펴볼만한 논문으로 한번은 끝까지 읽어보는 것을 추천하는 논문이다.
Abstract
WSSS는 pixel 수준의 annotation를 하는 인간의 노동력을 줄일 수 있다.
기존의 한계
- 최신의 기술들은 다양한 혁신적인 제약들과 heuristic rule에 의존하여 single mask를 생성한다.
- 다른 이미지들 간의 관계를 계산하는 것이 아니라 각각의 이미지를 독립적으로 다룬다.
업적
- 이미지를 넘어 관련된 영역을 연결해주는 이미지 간의 관계를 다룬다.
- 여기서 이미지를 넘어 관련된 영역이란 더욱 더 일관되고 전체적인 영역을 얻기 위해 계산될 수 있는 추가적인 관계가 존재하는 영역을 말한다.
- 이러한 정보를 끌어오기 위해 end-to-end cross-image affinity module을 제안한다.
- 이는 image 수준의 label만으로 pixel 수준의 이미지들 간의 관계를 얻어 낸다.
Introduction
Semantic Segmentation 최근 FCN(Fully Convolution Network)의 방법을 기반으로 좋은 성과를 내었다. 하지만, 이는 방대한 양의 dataset과 pixel 수준의 annotation이 필요하고 이는 구하기가 어렵다. 이에 따른 WSL(Weakly Supervised Learning) 방법들이 나오게 되었다.
WSL 방법들
- bounding boxes
- sparse scribbles
- image-level class labels
이 논문에서는 image 수준의 label 만 다룰 예정인데 이는 정확한 공간적인 정보를 다루기에 어려운 문제가 있다. 이를 해결해준 CAM의 방법이 있다.

하지만 CAM은 가장 구별되는 영역만 추출해내고 드문드문하며 불완전하다.
CAM의 방법을 고안하여 여러 WSSS 방법들이 제안되었다. 그 방법들은 아래와 같다.


순서는 제기된 년도순이 아니라 방법들의 흐름을 나타낸 것이다. 여기서 어떤 방법을 이용하였는가보다는 왜 이 방법들을 사용하였는지를 보면 하나의 이미지를 독립적으로 다루어 그 안에서 더 성능이 좋은 segmentation을 하기 위하였음을 알 수 있다.
이를 보완하고자 이 논문에서는 cross-image relationship을 제안하였는데 직관적으로 이해할 수 있는 이미지와 상세 설명들은 아래와 같다.

이 논문에서 사용한 end-to-end cross-image affinity module으로 segmentation network에 바로 적용 가능하다.
CIAN(Cross-Image Affinity Net) :: 다른 이미지들과 pixel 수준의 관계를 만드는데 두 가지 특징을 가진다.
- 본래의 representation을 정제하기 위해 relationships을 레버리지로 사용한다
- segmentation을 위해 더욱 통합적인 영역을 얻어낸다.
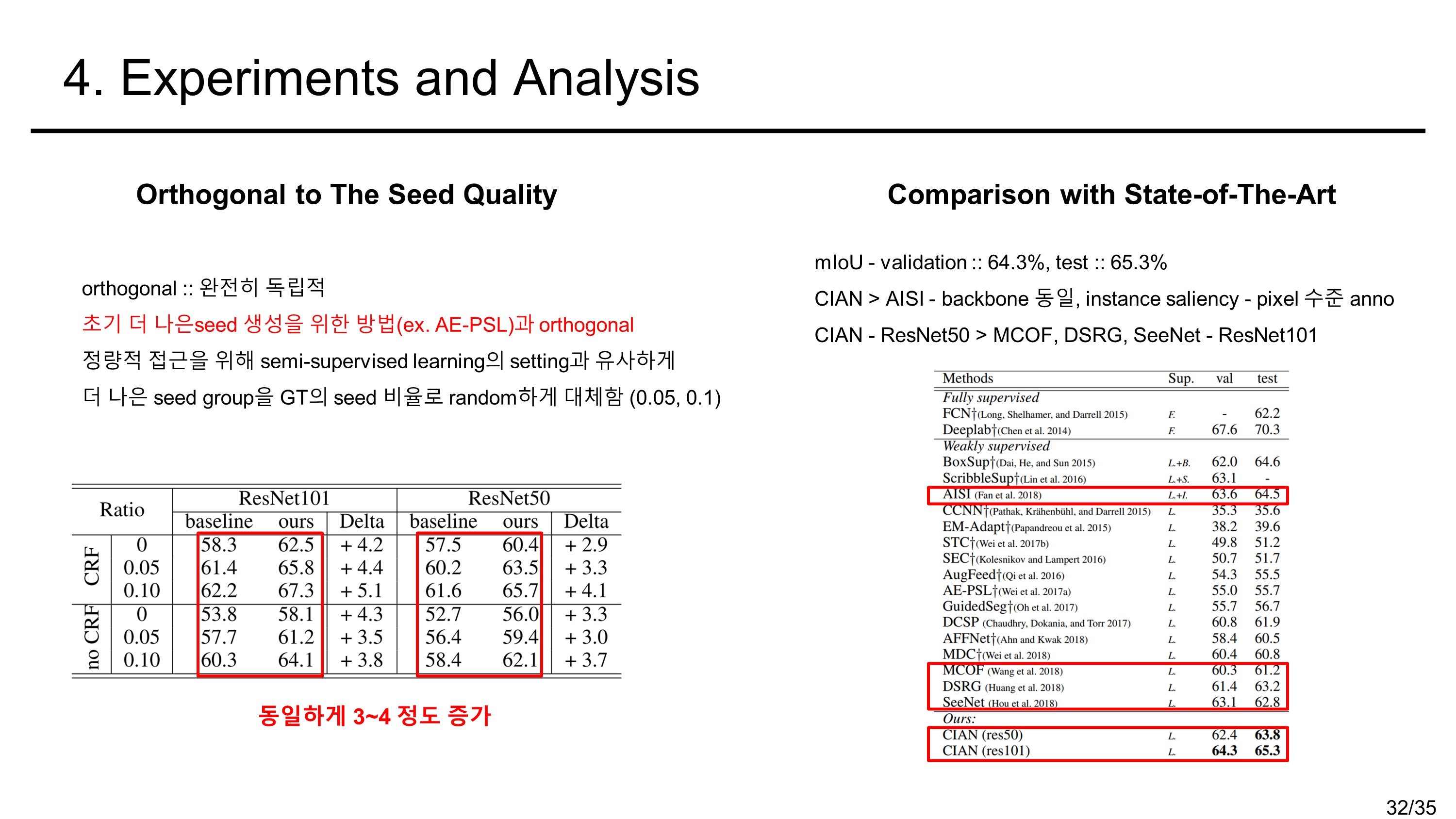
성능
Pascal VOC 2012 데이터 기준 validation set mIoU :: 64.3%, test set mIoU :: 65.3%의 성능을 보였다.
요약
- WSSS를 위한 cross-image relationship을 가진 model로 end-to-end cross-image affinity module을 제안하였다.
- 관련된 이미지들로부터 추가적인 정보를 제공하기 위해 제안하였고, 이를 통해 WSS를 위한 더욱 통합적인 영역이 얻어진다.
- cross-image relationships을 modeling하는 것의 유용함을 방대한 실험을 통해 증명해내었다.
- 이는 seed의 quality와 완전히 독립되므로 더 나은 seed를 훈련을 통해 계속하여 개선해나갈 수 있다.
- Pascal VOC 2012 데이터 기준 validation set mIoU :: 64.3%, test set mIoU :: 65.3%의 성능을 내었다.
Related Work
Co-Segmentation
주어진 이미지들 그룹에 대해 공통적인 object의 mask를 예측하는 것이 목표이다.
Chen, Huang, and Nakayama ; Li, Jafari, and Rother 2018; Li et al. 2018; Hsu, Lin, and Chuang 2018; Hsu et al. 2018
- 보편적인 object에 대해 class에 구애받지않는 mask들을 찾는 것에 초점을 둠
- 테스트할 시 공통된 object를 정의할 수 있도록 이미지들의 그룹을 입력으로 사용
- 많은 co-segmentation 방법들이 pixel 수준의 마스크로 학습함
본 Weakly-Supervised Segmentation에서는 class가 알려진 하나의 이미지가 입력으로 들어간다.
Li et al. 2018. Shen et al. 2017.
- WSSS에서 seed를 생성하기 위해 co-segmentation방법을 적용
본 affinity module은 seed를 대신하여 segmentation network들을 위한 end-to-end component임
Pixel-Level Affinity
AffinityNet (Ahn and Kwak 2018)
- CAM seed로 sparse한 점들을 추출함
- metric learning을 통해 추가적인 affinity net을 학습
본 affinity module은 다른 이미지들 간의 정보를 역동적으로 공유하는 end-to-end component임
Wang et al. 2017; Fu et al. 2019; Yuan and Wang 2018
- Non-local 접근방식으로 pixel 수준의 affinity가 통합됨
- 단일 이미지의 숨겨진 구조들을 발견하기 위해 long-range intra-image context에 초점을 둠
본 접근방식은
- weak label 문제 해결을 위해 공통된 object들을 강조하고
- 서로 다른 이미지에서 상호보완적인 정보를 공유하는 것
이 목표이다.
Our Approach

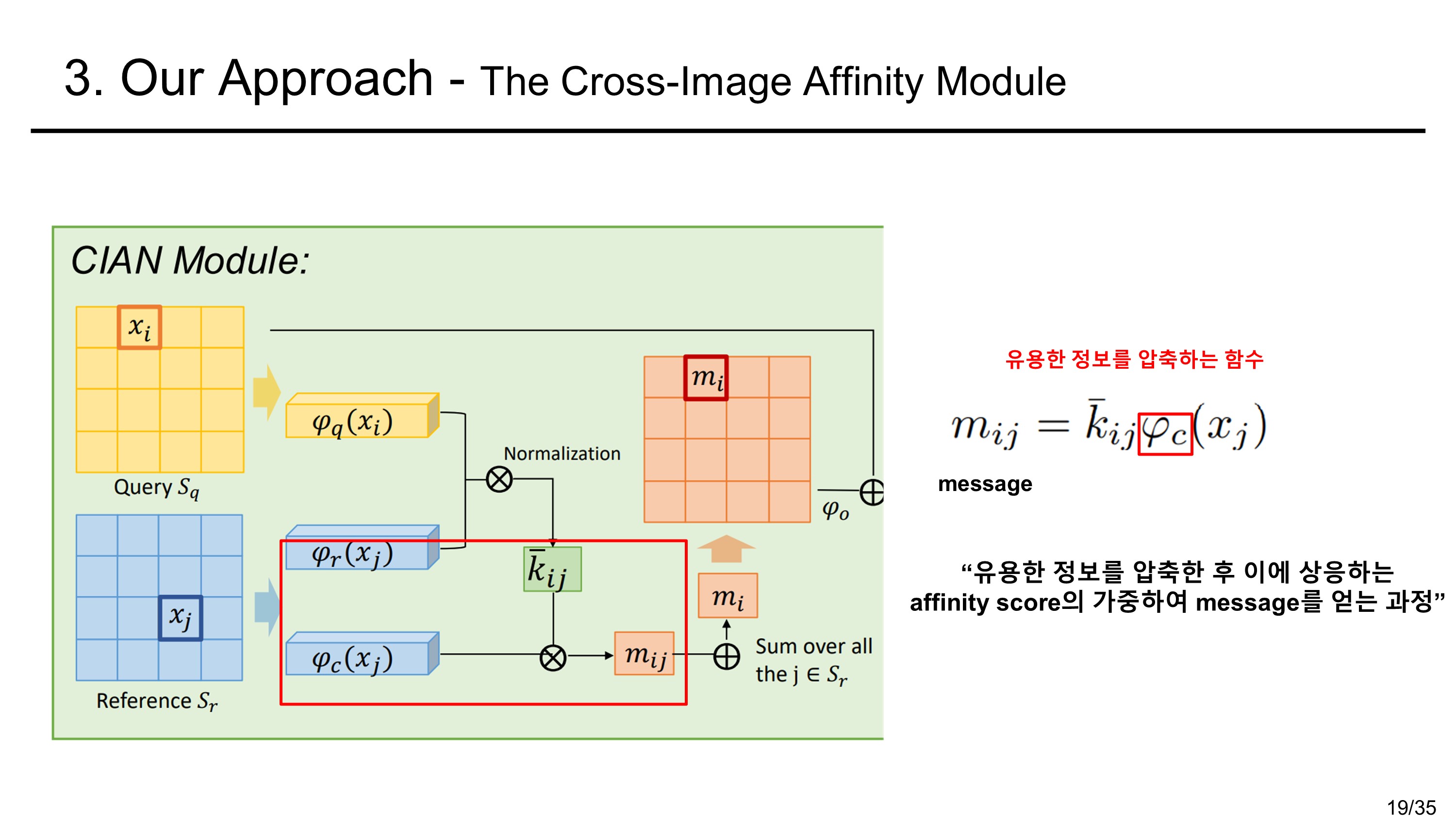
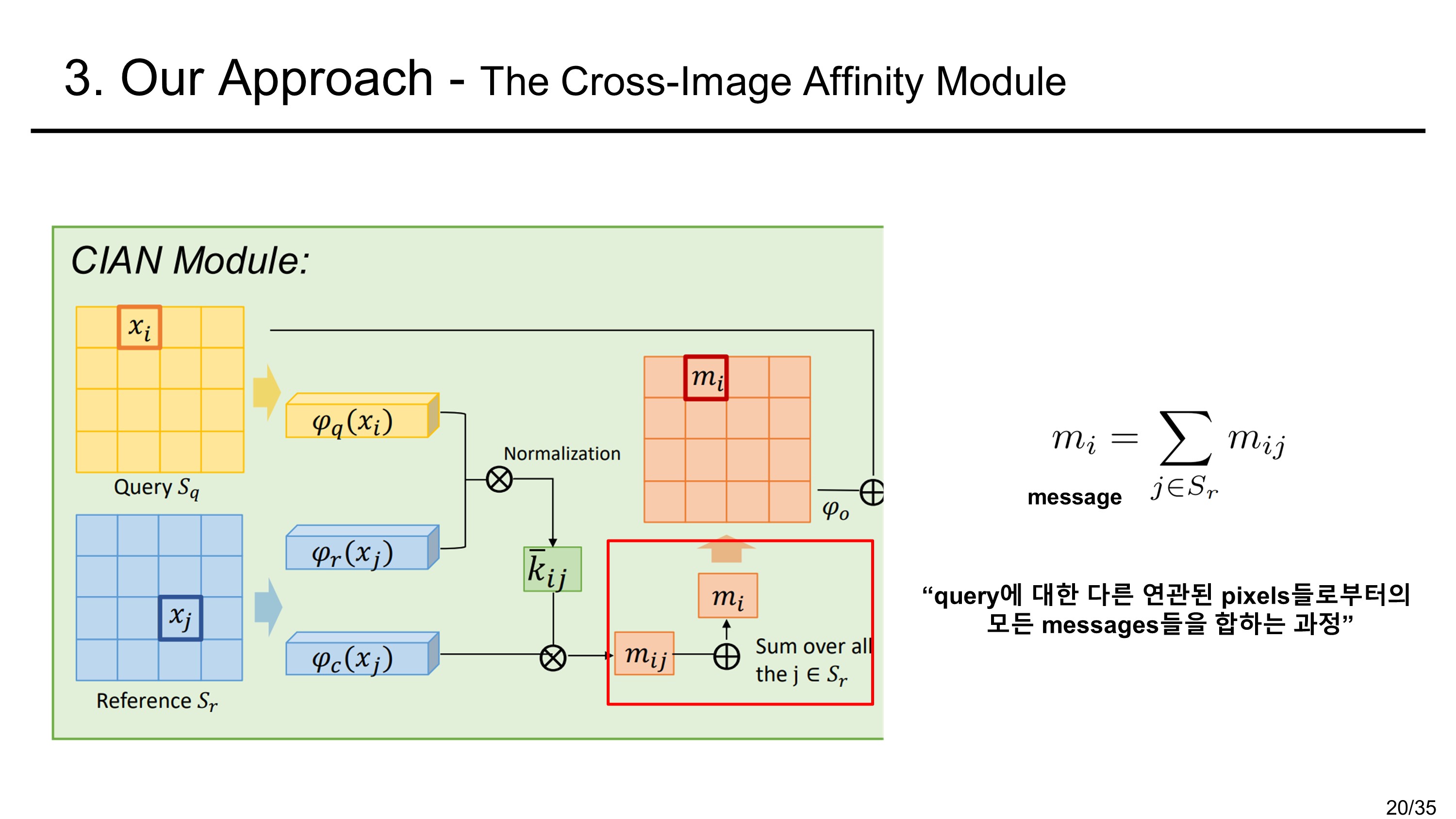
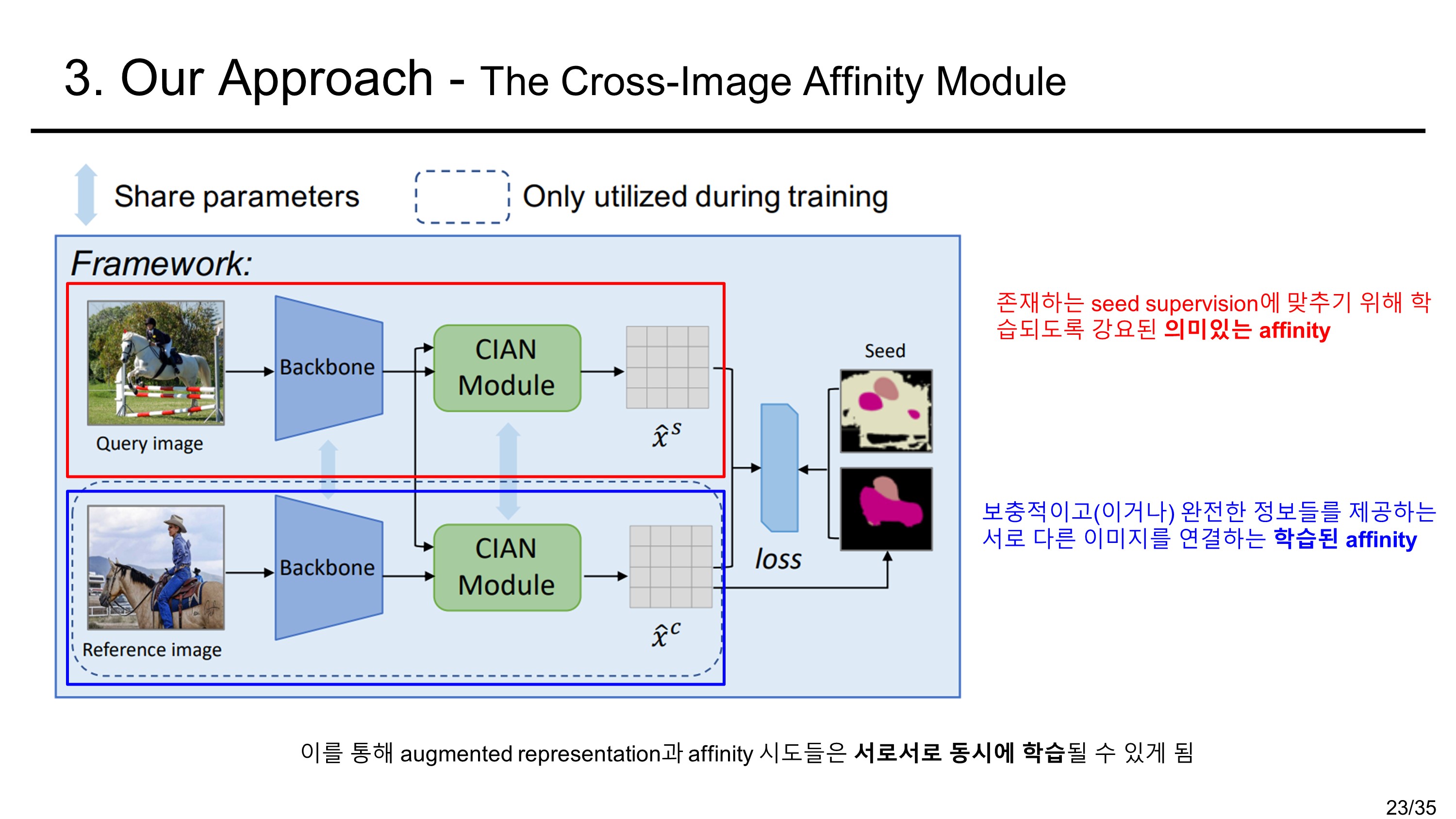
먼저 전체적인 구조를 보면 query image(inference를 할 image)와 reference image(참고할 image)를 입력으로 받는다. backbone과정에서 두 image의 feature를 다 추출하는데 parameter를 공유한다. 그래서 a siamese backbone이라 명명하였다고 한다. (샴 쌍둥이가 머리 둘에 몸이 하나인 쌍둥이 인것을 생각해보자.) backbone을 통해 나온 embeddded feature는 CIAN moduel에 들어가게 된다. 이제 CIAN module의 과정을 살펴보자.
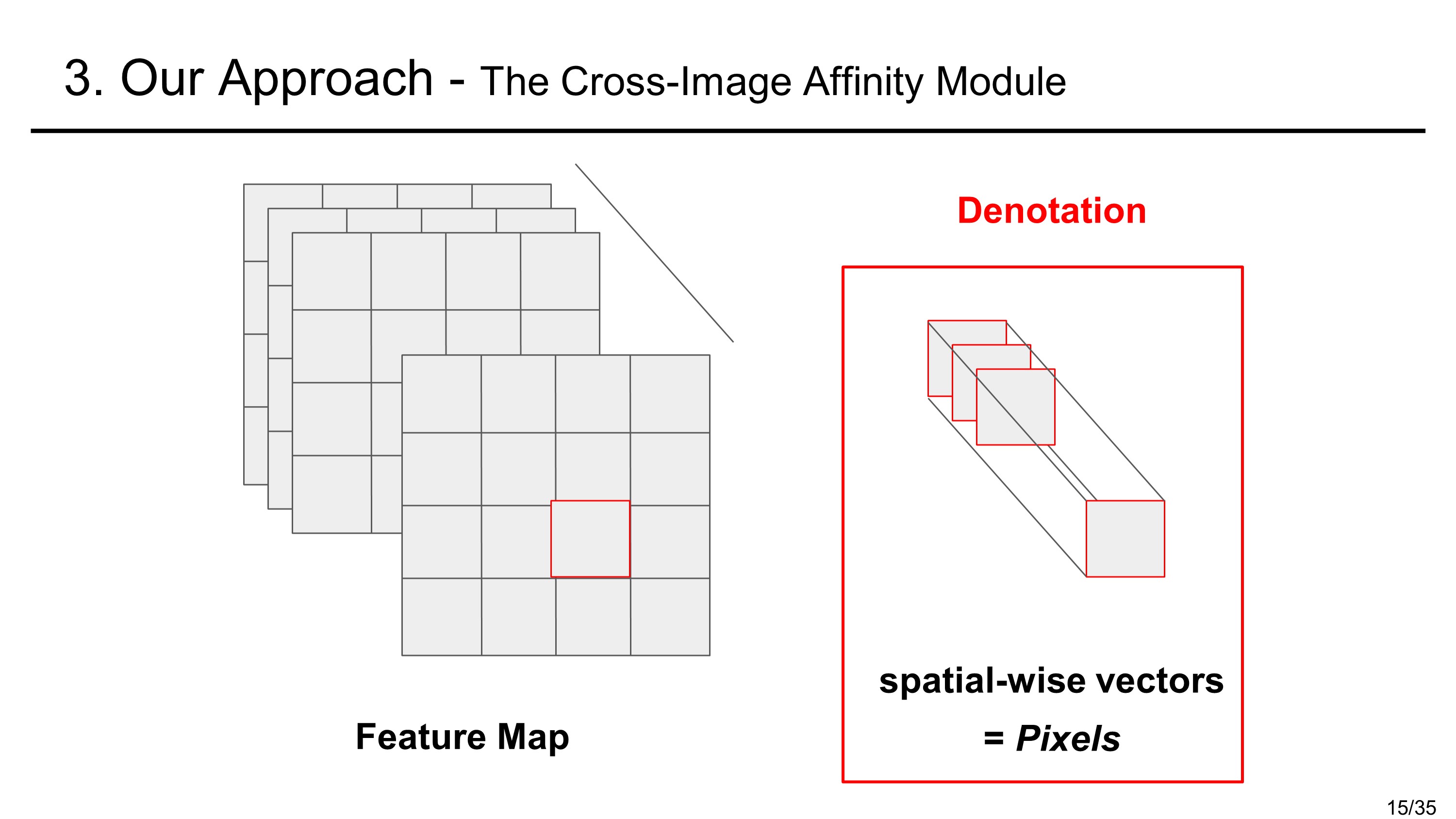
먼저, 표기에 있어서 pixel은 feature map에서 한 픽셀 부분의 공간 벡터를 나타낸다고 하자. 이후의 과정은 다음과 같다.
The Cross Image Affinity Module
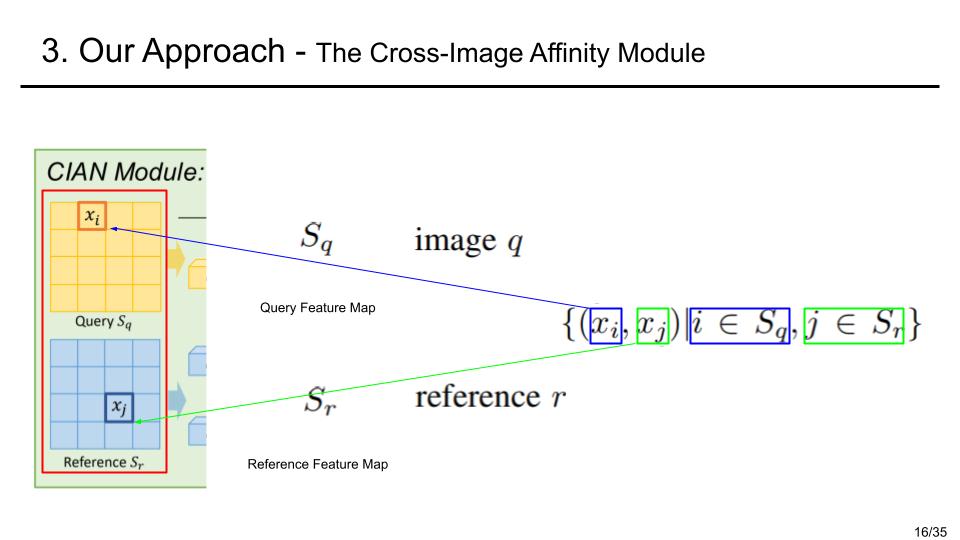
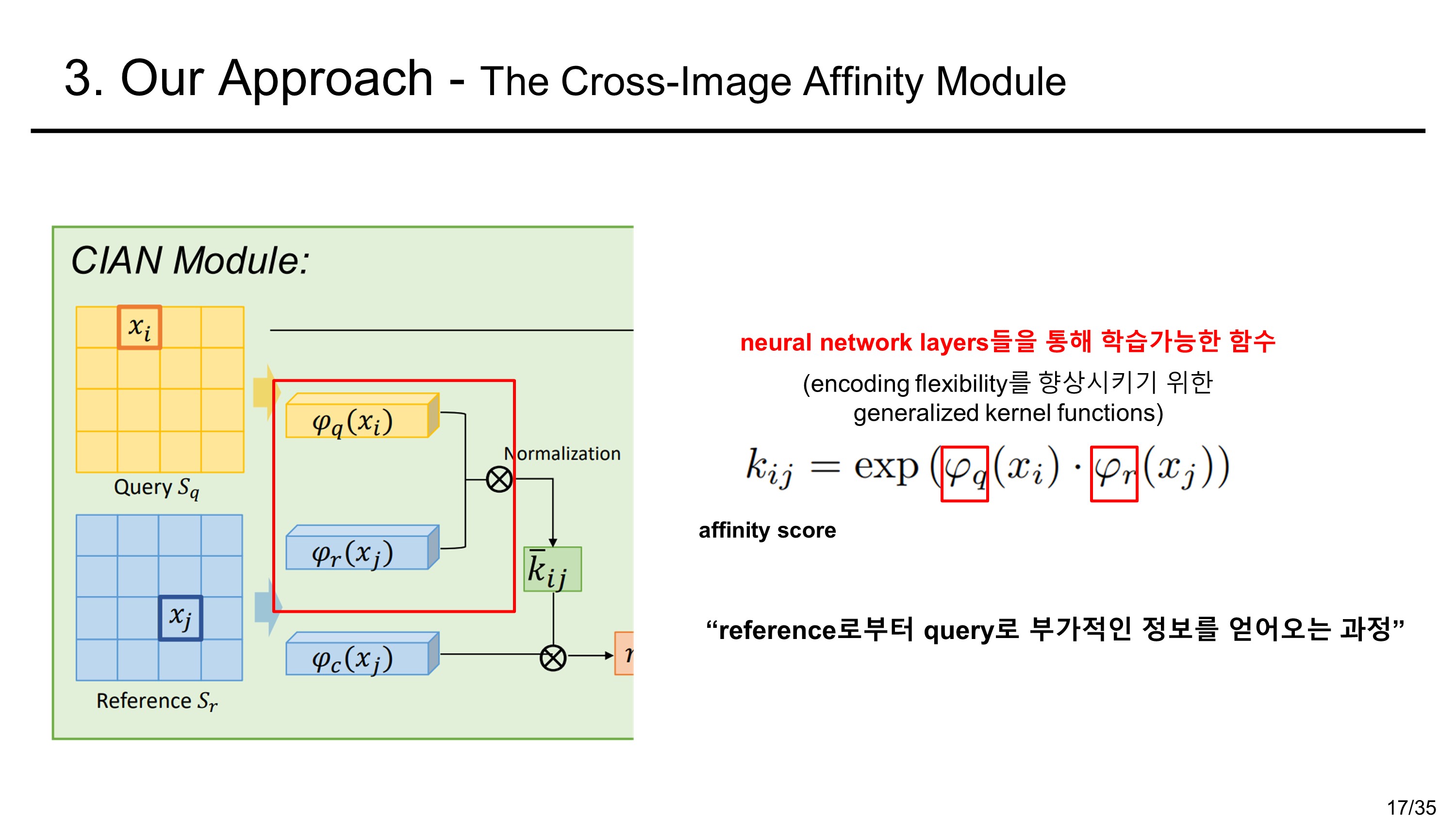
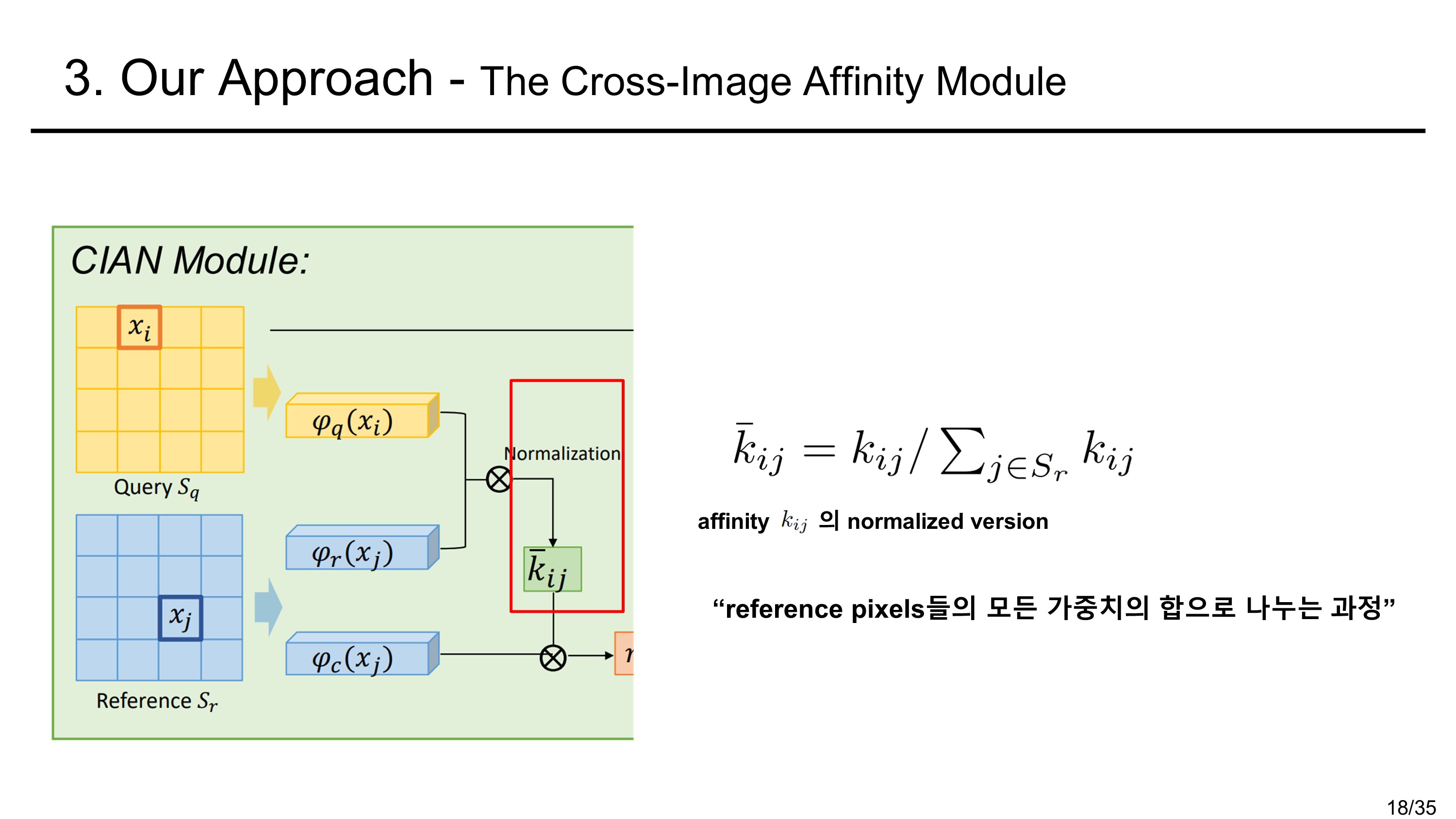


Multiple Pairs
앞의 살펴본 것은 reference image의 수가 한 장일 경우인데 여러 장일 경우는 주요부분을 다음과 같이 설명한다.

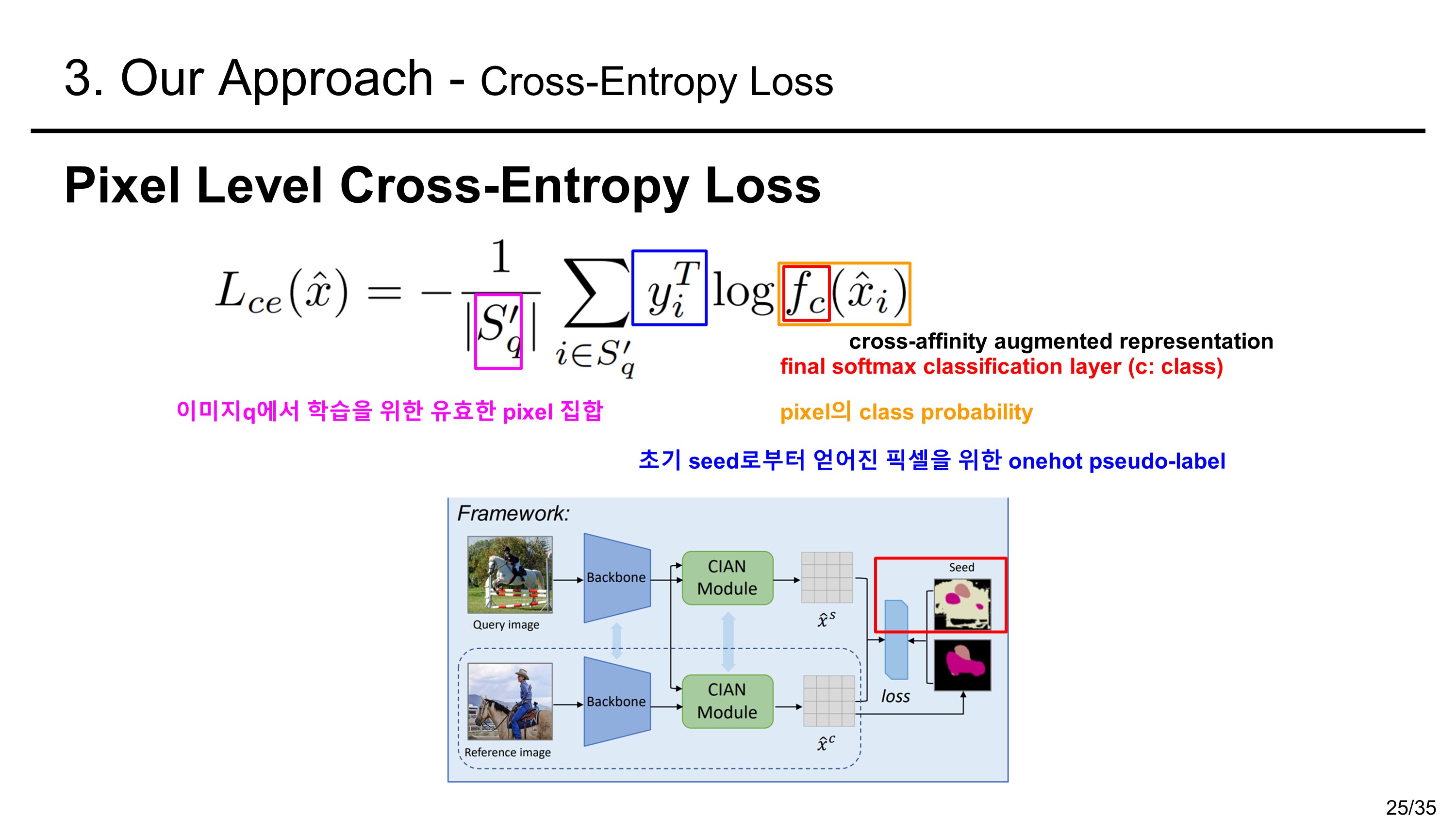
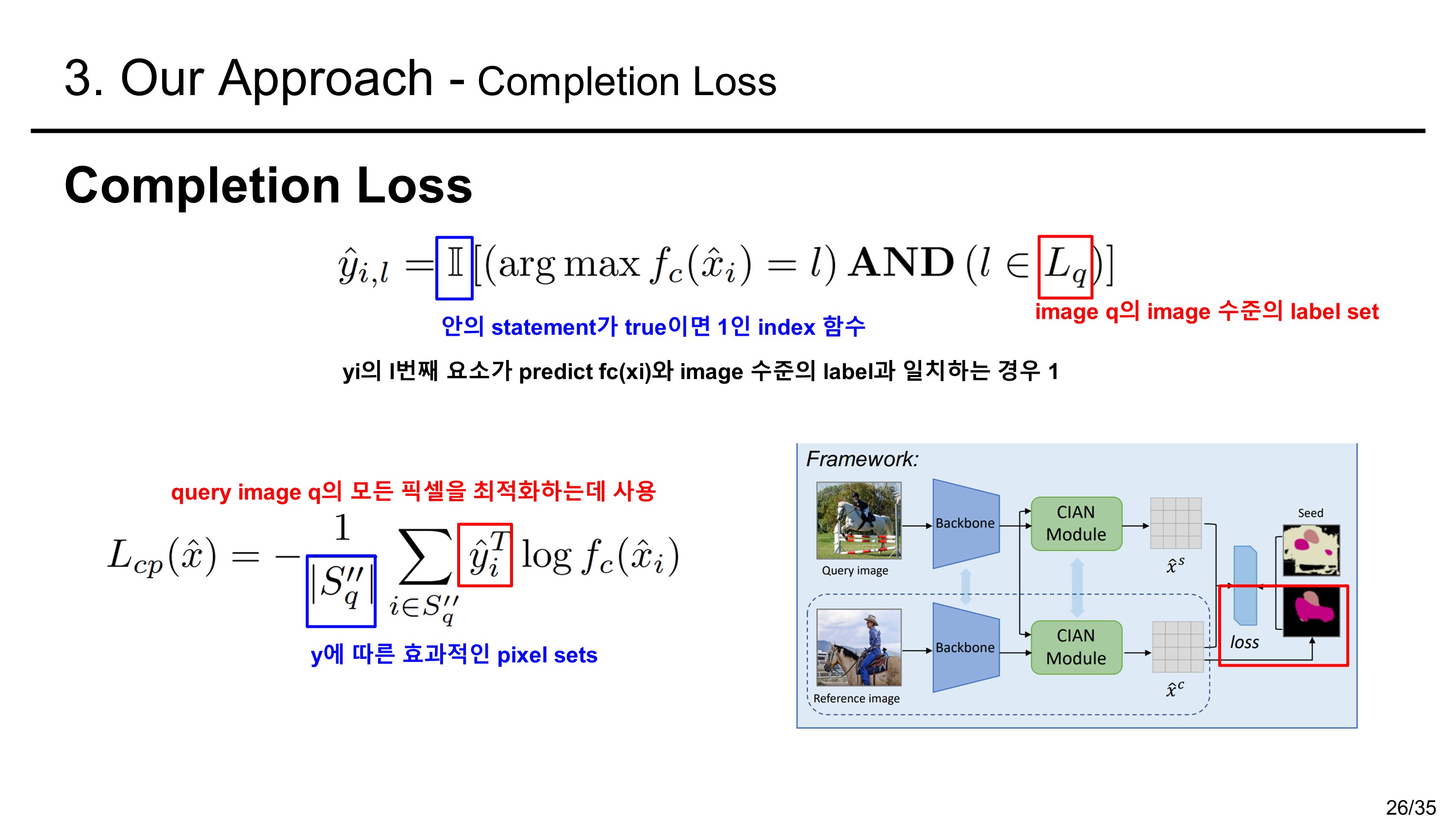
Cross-Entropy Loss
loss는 아래와 같이 cross entropy loss와 completion loss를 합하여 사용한다.

experiment


conclusion
- cross-image relationship의 leverage 사용을 제안하였다.
- 다른 이미지 간의 pixel 수준의 affinity를 build하는 CIAN module 적용하다.
- 이는 end-to-end model이며 segmentation network에 바로 적용가능하다.
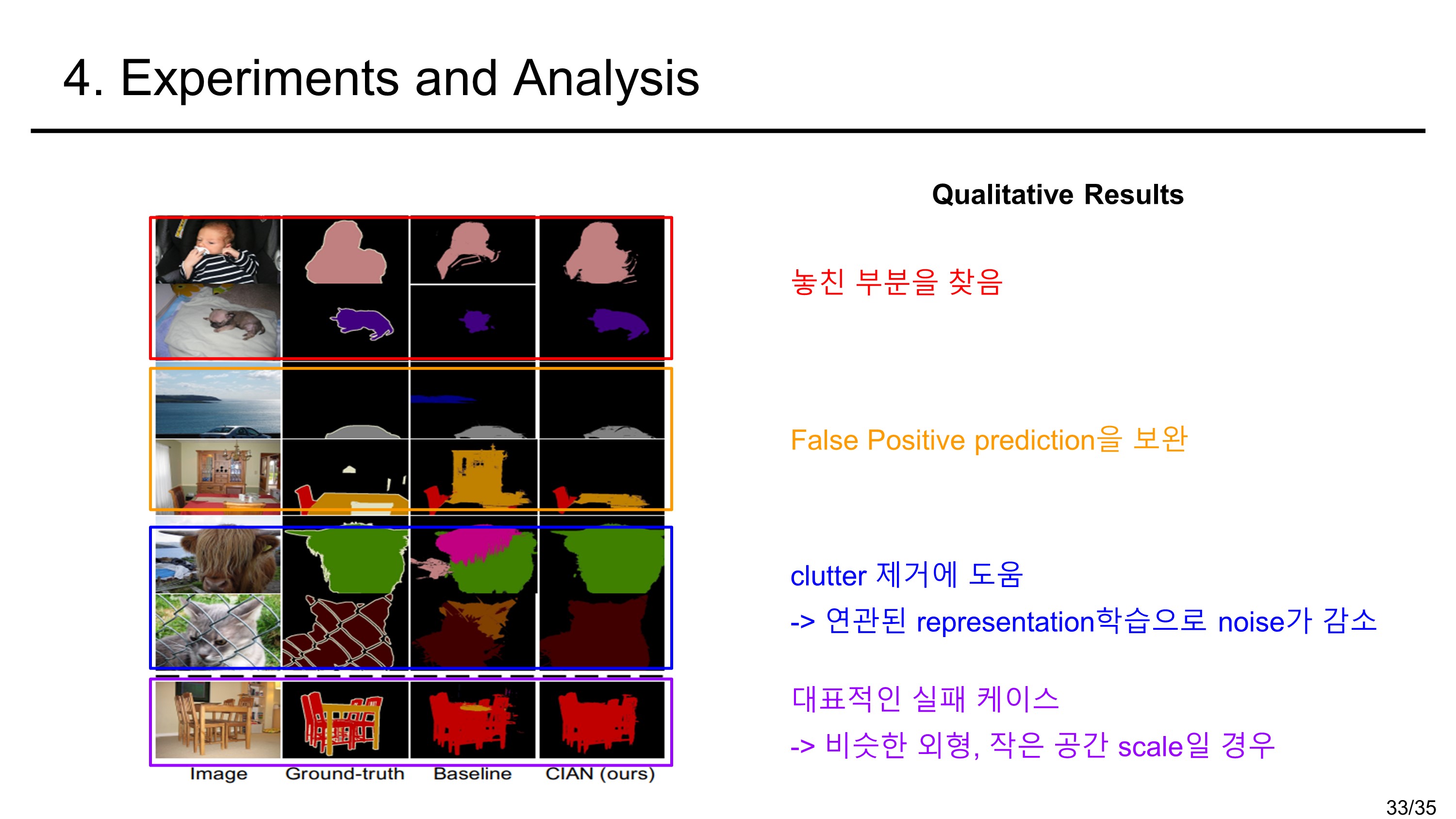
- cross-image relationship을 통해 더 전체 object의 영역을 추정 및 모호한 부분을 개선하였다.
- 방대한 실험을 통해 cross-image relationship의 장점을 증명하였다.
- VOC 2012로 semantic segmentation에서 SOTA 달성하였다.
'Theory > Computer Vision' 카테고리의 다른 글
| [Active Learning] Cost-Effective Active Learning for Melanoma Segmentation 논문 리뷰 (0) | 2022.08.23 |
|---|---|
| [Active Learning] Region-Based Active Learning for Efficient Labeling in Semantic Segmentation 논문 정리 (0) | 2022.08.22 |
| [WSSS] SEC 논문 정리 (0) | 2022.02.21 |
| [WSSS] OC-CSE논문 정리 (0) | 2022.02.14 |
| [WSSS] EADER 논문 정리 (0) | 2022.02.13 |



