
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- HookNet
- 프로그래머스
- Pull Request
- Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images
- 오블완
- vscode
- 히비스서커스
- Decision Boundary
- AIFFEL
- IVI
- logistic regression
- numpy
- 사회조사분석사2급
- WSSS
- 도커
- docker
- 티스토리챌린지
- Jupyter notebook
- docker exec
- cocre
- aiffel exploration
- 코크리
- ssh
- 백신후원
- GIT
- docker attach
- cs231n
- CellPin
- 기초확률론
- airflow
- Today
- Total
히비스서커스의 블로그
[Active Learning] Cost-Effective Active Learning for Melanoma Segmentation 논문 리뷰 본문
[Active Learning] Cost-Effective Active Learning for Melanoma Segmentation 논문 리뷰
HibisCircus 2022. 8. 23. 19:46이 글은 2017년 NIPS에 등재된 Cost-Effective Active Learning for Melanoma Segmentation 논문을 읽고 정리한 글입니다.

0. Abstract
제한된 양의 medical image training labeled data를 semantic segmentation위한 CNN을 효과적으로 학습할 수 있는 novel Active Learning Framework를 제안함
Contribution
- pixel-wise uncertainty를 modeling하기 위해 test time에 dropout하여 Monte Carlo sampling을 적용한 실용적인 Cost-Effective Active Learning 접근 방법을 사용하였음
- training의 performance를 향상 시키기 위해 이미지 정보를 분석하였음
1. Motivation
의학적 진단에서 주요 문제
- 의학 전문가 결정의 주관이 들어가며 이는 의학 전문가의 경험이 최종 진단 결과에 영향을 줌
- 사람이 진단하는 것은 매우 지루하고, 시간 소모적이며 주관적인 error가 발생할 수 있음
⇒ 이를 보완하고자 다양한 computer vision algorithm들이 등장하였음
CNN을 활용한 방법에서 문제
- 매우 방대한 양의 labeled data가 train을 위해 필요함
- 의학 분야에서는 전문가들의 수준 높은 label이 필요하기에 방대한 양을 쌓는 것은 어려움
Active Learning
- workload를 줄이고자 하는 접근 방법임
- unlabel 데이터 중 정보력 있다고 판단한 데이터들의 sample 들을 뽑아 label하여 순차적으로 training을 해나가는 것을 말함
- sample들을 뽑는 다양한 방법이 존재함
이 논문의 주요 contributions
- CNN과 CEAL(Cost-Effective Active Learning) 방법을 이용하여 medical image semantic segmentation을 위한 framework를 train하고 design함
- network의 내재적인 분포를 분석하기 위한 Monte Carlo Drouput에 근거하여 medical image를 위한 정보 번역을 발전시킴
Github
https://github.com/marc-gorriz/CEAL-Medical-Image-Segmentation
GitHub - marc-gorriz/CEAL-Medical-Image-Segmentation: Active Deep Learning for Medical Imaging Segmentation
Active Deep Learning for Medical Imaging Segmentation - GitHub - marc-gorriz/CEAL-Medical-Image-Segmentation: Active Deep Learning for Medical Imaging Segmentation
github.com
2. Related work
2-1. Cost-Effective Active Learning (CEAL) algorithm
Active Learning
- Active Learning은 human annotator에게 query하여 unlabeled data pool에서 새로운 labeled instance를 얻어내는 알고리즘을 말함
- data의 정보성과 uncertainty에 근거한 다양한 방법을 통해 후보군들을 뽑을 수 있음
Cost Effective methodology
- 일반적인 Active Learning과는 반대
- labeled 되지 않은 sample들을 자동적으로 선택하고 pseudo-annotation할 것을 제안
CEAL
Cost-effective active learning for deep image classification IEEE 2016
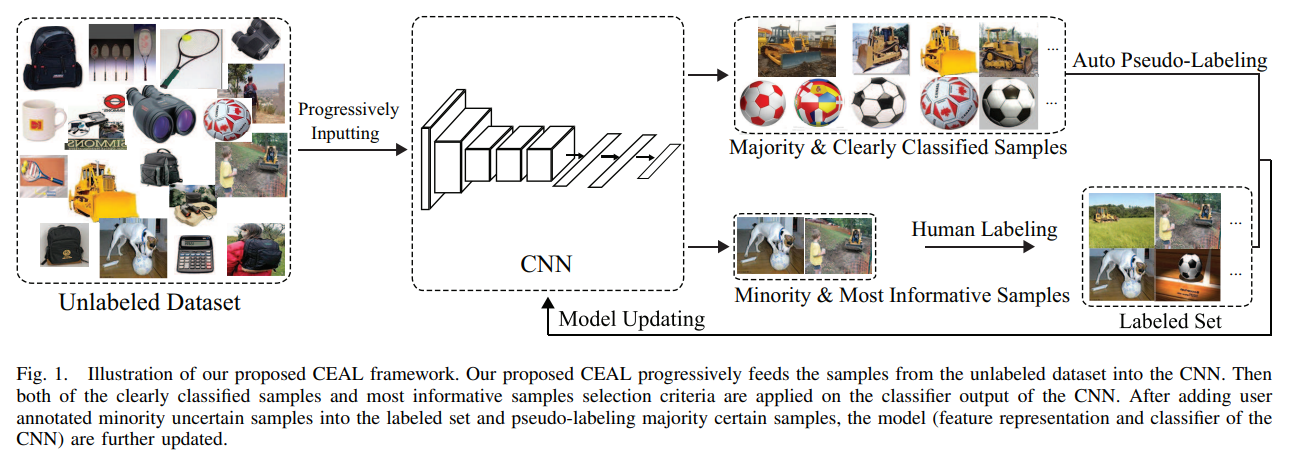
-
- prediction score가 낮고 most informative/uncertain sample
- oracle (human annotator)를 거쳐 labeled됨다른 confidence level에 근거하여 complementary sample selection을 진행
majority sample
- prediction score가 낮고 most informative/uncertain sample
- oracle (human annotator)를 거쳐 labeled됨
minority sample
- prediction score가 높음
- pseudo label을 할당함
2-2. CNN’s for Image Segmentation: U-Net architecture
- 생략
3. Proposed methodology
3-1. Image uncertainty estimation
Kullback-Leibler (KL)
Practical variational inference for neural networks NIPS 2011
- complementary sample selection을 위한 active learning의 기준은 unlabeled data의 내재적인 분포에 근거함
- posterior를 임의의 분포로 가정하고 posterior를 근사시켜야 함
- posterior를 임의의 분포에 가정할 시 사용하는 방법이 KL방법
- KL를 통해 두 확률분포(근사분포와 Posterior)의 차이를 최소화하여 network의 가중치 q(W)를 구할 수 있음
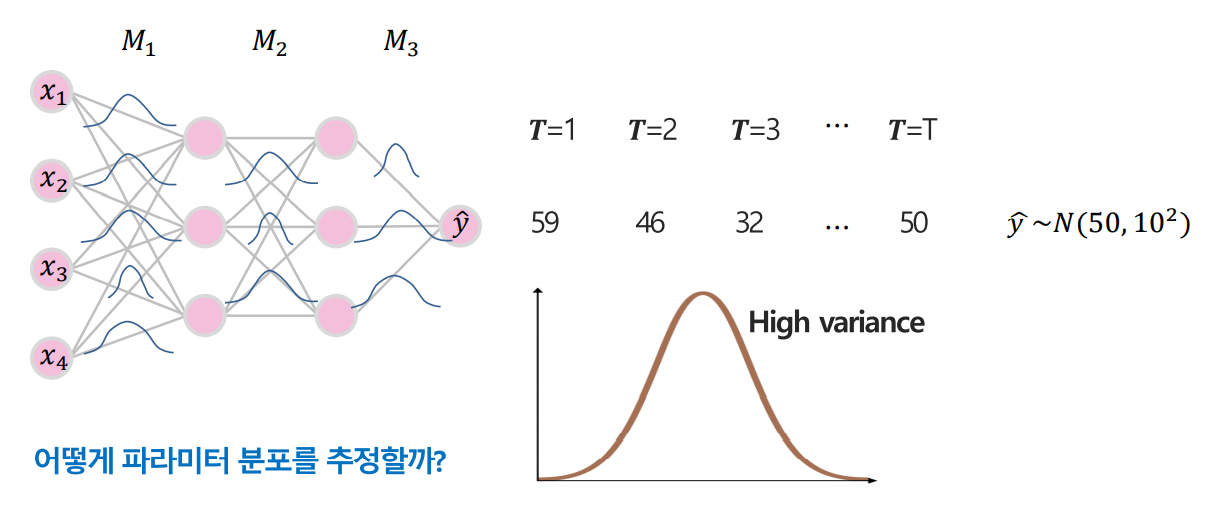
자세한 내용 (고려대학교 DMQA 연구실 자료를 바탕으로 이해한대로 정리하였습니다.)
우리는 Test Time에서의 여러 결과값들의 분포를 통해 파라미터의 분포를 추정하고 싶은 것인데 이를 어떻게 추정할 것인가를 생각해보아야 한다.
파라미터 분포는 아래의 Posterior 식으로 나오게 되는데 이는 베이즈 정리를 통해 우측의 식으로 나타낼 수 있다. 그런데 우측의 식에서 분모인 Evidence 부분은 일반적으로 구하기가 어렵다.

따라서, 다른 방법으로 접근을 해야 하는데 이는 임의의 분포를 가정하고 이를 Posterior와 비슷하게 근사하는 방법이 있다.
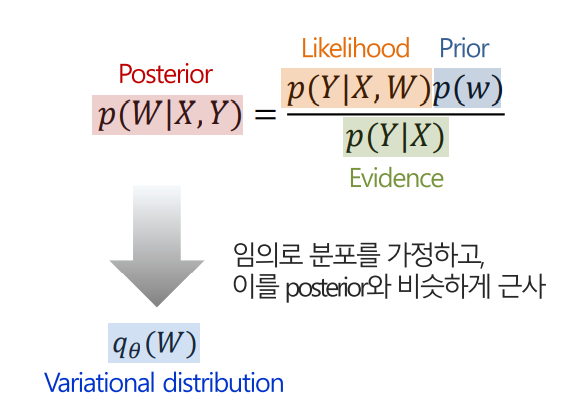
이를 Kullback-Leibler Divergence를 통해서 두 확률분포의 차이를 계산할 수 있고 이를 최소화 시키는 파라미터를 추정할 수 있는 것이다.

결론적으로, Test time에서의 파라미터 분포를 추정하기 위한 방법으로 제안된 것이 Kullback-Leibler 방법이다!
Monte Carlo Dropout
Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding 2015
- q(W)를 추정하고자 Monte Carlo Dropout을 사용하여 가능성을 찾음
dropout
- 각 layer마다 확률이 기본확률이 p인 Bernoulli distribution을 따르며 네트워크 활성화를 무작위로 비활성화 시킴
Bayesian convolutional neural networks with bernoulli approximate variational inference 2015
- training 시에는 overfitting을 방지해줄 뿐 아니라
- test time시에 활용하면 pixel-wise sample uncertainty를 도입할 수 있음
- Ix(이미지의 픽셀), dropout의 효과에 의해 동일한 픽셀에 대한 T 개의 서로 다른 예측의 분산을 계산하는 Iy(이미지의 픽셀에 대해 예측된 label)의 불확실성을 추정할 수 있음
- pixel-wise uncertainty maps의 정확성은 Dropout의 step인 T와 Dropout의 확률인 P에 의해 결정됨
→ P의 값이 높으면 variation이 큰 것이므로 일관된 결과를 만드는 것이 어려움 (T가 유한할 때)
⇒ 위 논문에서 최적의 P는 0.5이고 가장 좋은 정확도를 가질 때는 T를 무한대로 하였을 때임을 밝혀진 바가 있음
이 논문에서는
- 위 방법이 CEAL 방법과 통합되려면 pixel wise uncertainty는 prediction confidence를 측정하기 위해 정수가 변형되어야 함
→ 가장 의심스러운 segmentation에 더 높은 점수를 부여하도록 uncertainty map으로부터의 모든 픽셀값을 더하는 것을 제안
- additional weighting step
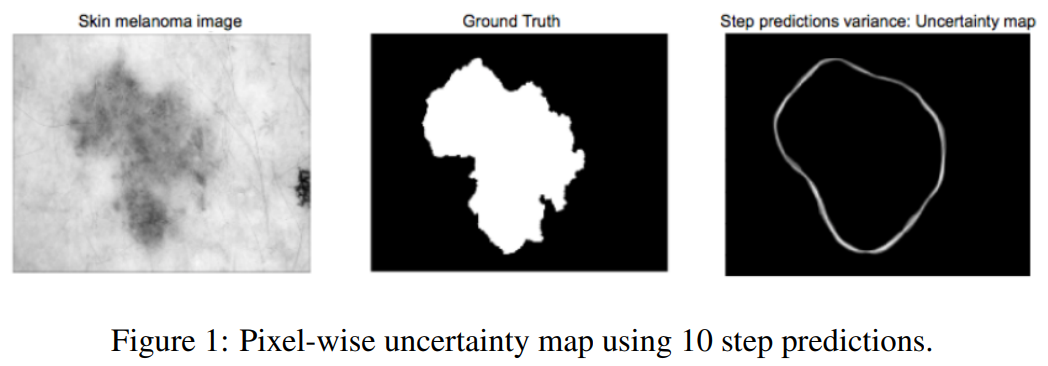
문제점
- 단순히 더하는 것은 윤곽 전반에 걸친 예측의 변동성을 반영하지 못함
- 윤곽에서 멀수록 예측에 대한 전체 불확실성의 기여도가 더 높아야 함
해결
- 예측한 segmentation 에 대한 distance map을 계산 (이를 통해 가중치를 부여함)
Linear time euclidean distance transform algorithms IEEE 1995
- 이는 윤곽의 가장 가까운 픽셀까지 각 픽셀의 euclidean distance로 이루어짐
- 이 distance map과 uncertainty map을 곱하여 윤곽과 멀어질수록 더 높은 점수를 얻게 됨
- 직관적으로 uncertainty map에서 더 두꺼운 윤곽선은 더 두껍게 더 얇은 윤곽선은 더 얇게 만들어줌
3-2. Complementary sample selection
일단 uncertainty score가 정의되면 예측에 대한 정확도와 연관하여 시각화하였음
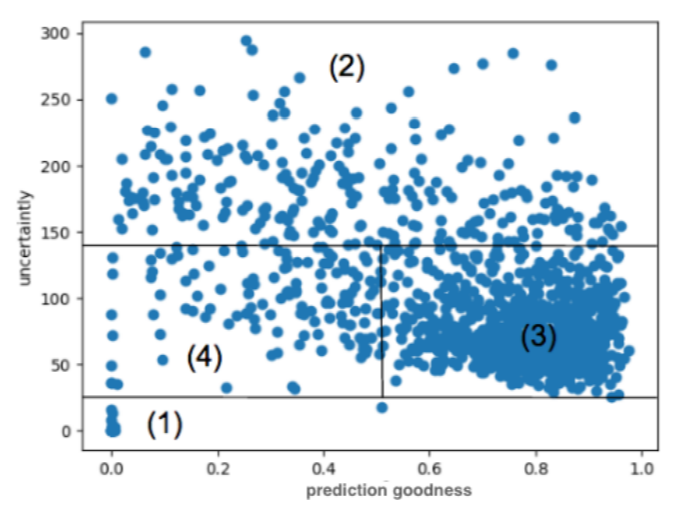
uncertainty와 accuracy에 연관성을 시각화함
(1) Undetected melanomas
→ high certainty를 가졌으나 missing detection
(2) Highly uncertain samples
→ oracle에게 annotation 될 sample들
(3) Certain Samples
→ 가장 흔한 케이스로 pseudo label을 해야함
(4) Uncertain and wrong predictions
→ 가장 안 좋은 케이스로 active learning 알고리즘을 반복하여 줄여야 함
⇒ ground truth를 가지고 한 것이라 가능한 일이기에 실제는 uncertainty 값만 추정할 수 있음
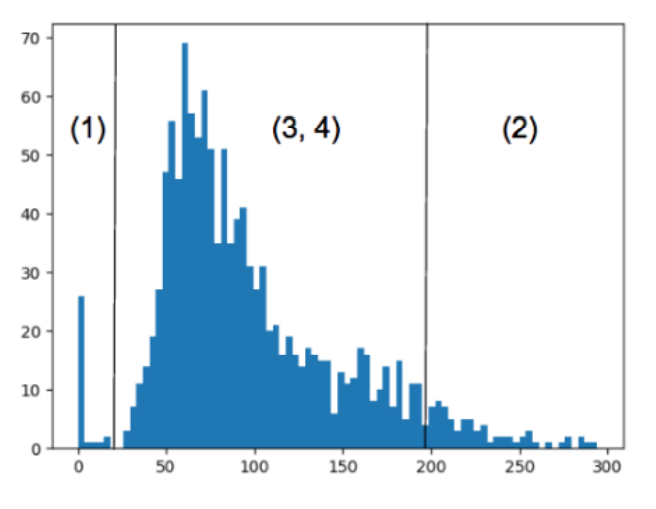
uncertainty의 histogram을 시각화 함
→ 위의 visualization을 uncertainty에 사영하여 count한 것
유의해야 할 점
- (3) 과 (4)가 섞임
complementary sample selection 시
⇒ 각 영역에 대해 올바른 비율의 sample을 순차적으로 선택하여 over-fitting을 방지하며 network의 성능을 점진적으로 향상시키는 전략을 계획해야 함
4. Results and Future work
ISIC 2017 challenge dataset :: Skin Lesion Analysis towards melanoma detection
- pixel-wise segmentation 되어 있음
- active learning scenario를 가정하기 위해 일부만 GT로 사용하여 초기 network를 학습하는 용도로 사용
- 나머지 GT는 human annotator가 제공하는 것처럼 활용
변형
- origin: 2,000 RGB dermoscopy image + binary mask
- modified: Gray scale image, 이미지 사이즈 조절 CNN input에 맞게 조절 (UNet)
학습
- training set은 Cost-Effective Active Learning 방법론에 근거하여 초기화함
- label data를 랜덤으로 추출한 후 나머지는 label을 지움
Imagenet classification with deep convolutional neural networks 2012
- data augmentation을 적용함
active learning loop의 각 반복에서 sample의 선택은 heuristic parameter로 근거하였음
초기 600개의 sample로 학습을 시작하여 매 반복마다 1000개의 이미지를 label하여 학습에 추가함
매 반복마다 제기된 알고리즘은
- melanoma가 없는 이미지들 중에서 10개
- uncertainty가 높은 이미지들 중에서 10개
- 랜덤하게 15개
를 추출하였음
또한, 특정 임계값 이상의 confidence score를 가지면 pseudo label하여 training set에 추가하였음
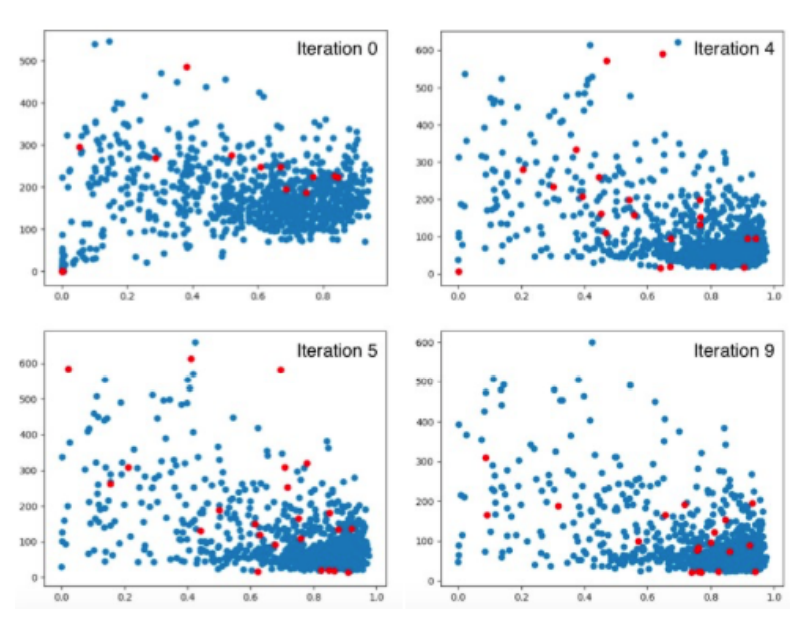
0, 4, 5, 9번째 반복에서 선택된 sample을 나타낸 것
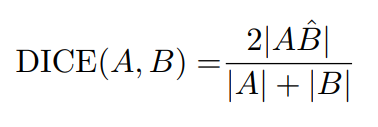
segmentation의 정량적 평가는 Dice coefficient로 계산함
9번 반복의 active learning 후 (CNN은 2epoch씩 함) 74%의 성능을 보임
⇒ 9번 반복 후에도 (4)에 여전히 sample이 있음을 나타냄
'Theory > Computer Vision' 카테고리의 다른 글
| [Calibration] Bridging Precision and Confidence: A Train-Time Loss for Calibrating Object Detection 논문 정리 (1) | 2023.11.23 |
|---|---|
| [Active Learning] Region-Based Active Learning for Efficient Labeling in Semantic Segmentation 논문 정리 (0) | 2022.08.22 |
| [WSSS] CIAN 논문 정리 (0) | 2022.03.10 |
| [WSSS] SEC 논문 정리 (0) | 2022.02.21 |
| [WSSS] OC-CSE논문 정리 (0) | 2022.02.14 |



