
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- AIFFEL
- 티스토리챌린지
- CellPin
- 기초확률론
- numpy
- docker attach
- 백신후원
- docker exec
- logistic regression
- airflow
- 사회조사분석사2급
- docker
- WSSS
- 히비스서커스
- 코크리
- 오블완
- cs231n
- vscode
- 도커
- GIT
- Pull Request
- IVI
- aiffel exploration
- cocre
- Decision Boundary
- Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images
- Jupyter notebook
- ssh
- 프로그래머스
- HookNet
- Today
- Total
히비스서커스의 블로그
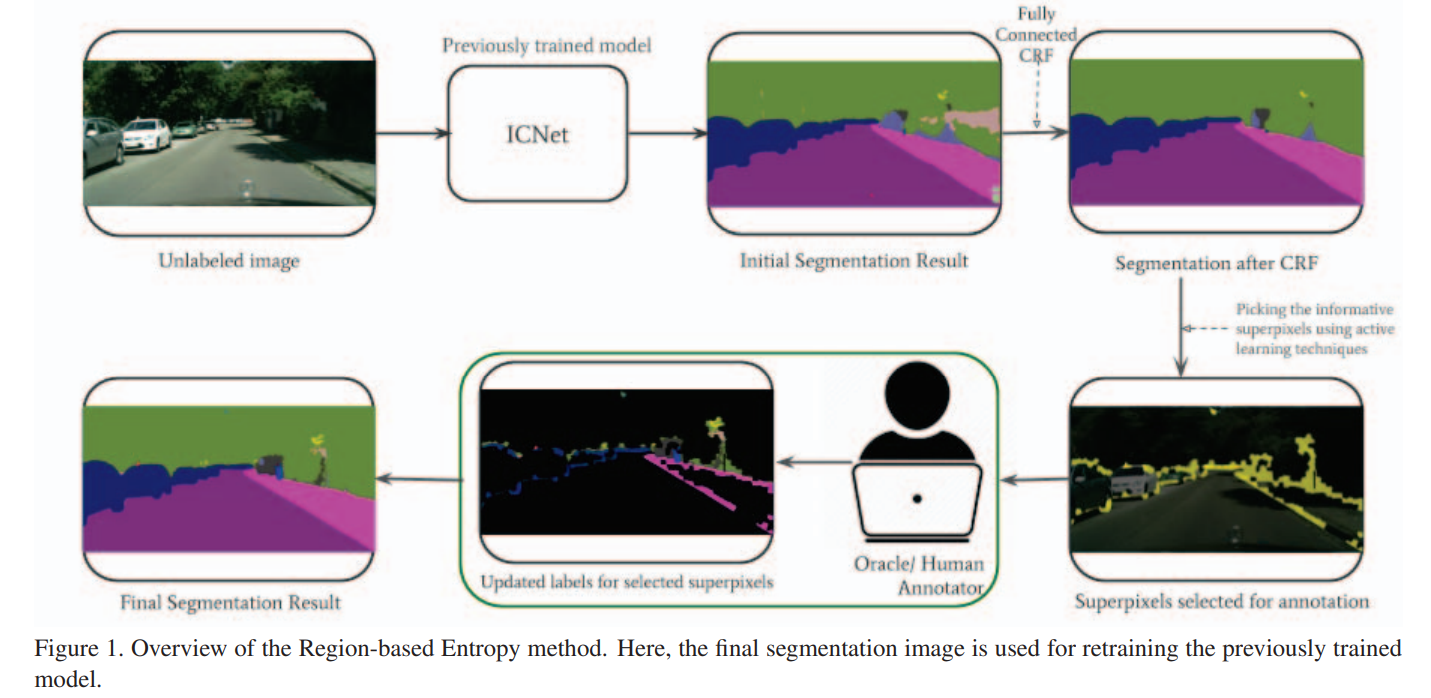
[Active Learning] Region-Based Active Learning for Efficient Labeling in Semantic Segmentation 논문 정리 본문
[Active Learning] Region-Based Active Learning for Efficient Labeling in Semantic Segmentation 논문 정리
HibisCircus 2022. 8. 22. 23:38이 글은 2019년 IEEE 저널에 실린 Region-Based Active Learning for Efficient Labeling in Semantic Segmentation 논문을 읽고 정리한 글입니다.
0. Abstract
annotated dataset의 필요성은 증가하고 있으나 모든 픽셀을 annotation 하는 것은 방대하기에 비용이 많이 듦
⇒ semantic segmentation task에서 region-based active learning 방법을 제안
- train dataset에 대해 각 이미지의 10%만 annotation 하여서 train dataset를 annotation한 모델의 93.8%의 성능을 보임
- transfer learning을 적용할 때에도 잘 작동하였음 (Cityscapes → Mapillary)
- Cityscapes dataset vs Mapllilary dataset
1. Introduction
Vision Task
- 자율주행과 같은 real world task를 위해서는 방대한 양의 데이터가 필요함
- 이를 위해 더욱 효율적으로 dataset을 생성하도록 하는 더 나은 방법이 필요하며 이와 같은 방향으로 노력하고 있음
Semantic Segmentation
- 많은 관심을 받고 있으나 모든 픽셀을 annotation하는 것은 시간과 자원 부족함
- semi-supervised method가 대두되고 있으나 아직은 full supervised method가 SOTA임
⇒ 이 논문에서는 annotation 업무량을 줄이고자 함
Active Learning
- 주어진 model을 이용하여 데이터를 골라서 oracle(annotator)에게 query를 날려 고른 데이터의 label를 맡김
- 하지만
- algorithm에 근거한 것으로 focus가 다름
- real-world task에서 명백한 개선된 점을 보여주지 않음
⇒ 주 목적이 active learning을 통하여 unlabeled data에 대한 annotation cost를 줄이는 것이 목표
이 논문에서는
- entropy-based active learning 방식을 사용
- 과거에 entropy는 classification에서 active learning을 위해 많이 쓰였지만
- 이번에 예외적으로 semantic segmentation task에 적용하려 함
- region-based active learning 방법으로 annotation cost를 줄임
- label의 뻗어나감을 위한 fully connected Conditional Random Fields (CRF)와 함께
- superpixel 수준의 이미지를 annotation함으로써
Contribution
- CNN에 근거한 semantic segmentation의 active learning 방법은 최초의 시도
- label effort를 줄이기 위해 픽셀 수준에서 fully connected CRF의 dense connectivity를 활용함
- Cityscapes dataset에서
- train dataset에 대해 각 이미지의 10%만 annotation 하여서 train dataset을 annotation한 모델의 93.8%의 성능을 보임
- Mapillary dataset 에서
- Transfer learning을 통해 train dataset에 대해 각 이미지의 10%만 annotation 하여서 train dataset을 annotation한 모델의 90%에 가까운 성능을 보임
2. Related Work
Active Learning
가장 정보력있는 data point를 orcale에게 query 날리도록 여러 기준들이 제기되었음
Active learning with gaussian processes for object categorization , Heterogeneous uncertainty sampling for supervised learning
- query를 선택하는 방법으로 uncertainty-based 측정 방법들을 제기하였음
Active Learning for Semantic Segmentation with Expected Change
- 현재의 모델을 가장 크게 변화 시킬 것으로 예상되는 data point를 선택함
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?
- Vision Task에서 Bayesian Deep Learning 모델의 Epistemic and Aleatoric uncertainty를 추정함
Cost-Effective Active Learning for Melanoma Segmentation
- Monte Carlo sampling으로서 dropout을 test time을 적용하여 pixel wise uncertainty를 얻음
- Cost effective active learning 접근법을 제안
Active Online Learning for Interactive Segmentation Using Sparse Gaussian Processes
- segmentation을 얻기 위해 foreground object와 Sparse Gaussian Process를 query로 날림
Region-Based Method
- 예전부터 잘 쓰였으며 지금은 semantic segmentation model에 통합되었음
- 전형적인 방법은
- 일정한 기준을 만족할 때까지 이미지를 일관된 작은 영역으로 나눔
- 일관된 작은 영역은 주어진 이미지의 seed region이 되고 object 전체 영역 혹은 일부를 label하게 됨
- 만약 seed regions을 넘어선 label들은 주변의 픽셀들로 구별됨
- 이를 active learning에 label propagation을 위한 접근법으로 사용함
3. Region Based Active Learning for Semantic Segmentation

input:
(i) X - 전체 데이터, P - labeled , Q - unlabeled
(ii) O - oracle (annotator) :: Q의 원소에 label을 하여 P의 원소로 만듦
(iii) Θ - deep learning model :: P에 대해 학습된 model
(iv) m - Q의 각각의 이미지 대한 annotation 비율
(v) b - group의 개수, l - group의 사이즈
output: updated model Θ
(1) Q의 부분집합 B를 선택 (Uncertainty가 가장 높으며, 사이즈는 l)
(2) B에서 m비율 만큼의 픽셀을 oracle O에게 query를 날림
(3) (2)에서 label을 얻은 B로 Θ를 retrain
(4) 회수 추가, Q에서 B를 빼냄
algorithm 1에서 쓰인 uncertainty에 대해 4가지의 uncertainty 측정 전략으로 기술
3.1.1 Image-level Entropy:
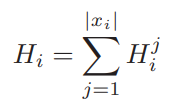
image xi 안에 있는 모든 픽셀에 대한 uncertainty를 더함
- model Θ로 uncertainty를 구한 후 ranking 순서대로 정렬한 후 l개의 이미지를 선택함
- 총 l x b개수의 이미지를 annotation함 (전체 Q보다 작게 하였음)
3.1.2 Pixel-level Entropy:
$$ p(c_k/x_i), k \in \{i,...,C\} $$
probability score map :: p(ck/xi), C: class의 수, k는 class 중 하나
$$ p(c_k/x^j_i), j \in \{i,...,|x_i|\} $$
probability score p(ck/xji), xi: 픽셀의 수, j는 픽셀 중 하나
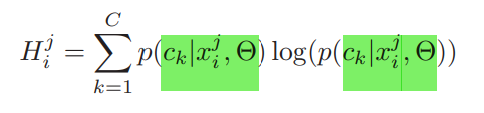
- entropy는 각각의 이미지 xi에 대해 개별적으로 계산됨
- image-level entropy (3.1.1)를 통해 구한 entropy에 따라 모든 이미지에 대해 ranking
- pixel-level entropy (3.1.2)를 기반으로 각각의 이미지에서 annotation의 비율 m만큼을 선택함
3.1.3 Edge Pixel-based Entropy:
- misclassification 비율은 boundarys/edges 에서 더 많이 발생함
- 이는 edge pixel들이 더 높은 uncertainty를 가지고 있다는 것을 암시함. 하지만,
- 객체 내부의 작은 edges, 일부 boundary pixel들
- 오분류 되기 쉬우나 uncertainty가 높지 않음
- 이를 반영하여 Canny edge detector를 통해 edge를 식별하고 가중치를 부여함
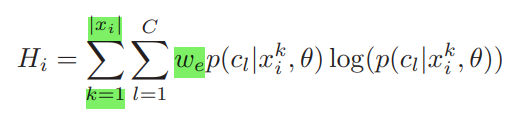
- edge에는 1보다 큰 가중치를 edge가 아닌 곳은 1의 가중치를 부여
3.1.4 Region-based Entropy:
- semantic segmentation에서 이웃하는 픽셀은 매우 가까운 관계를 가지기 쉬우며 비슷한 정보를 공유기에 같은 class에 속하기 쉬움
⇒ 각각의 pixel의 entropy는 독립적이며 이러한 관계를 고려하지 않음
- 이미지에 superpixels을 적용하여 region based strategy를 제안함
- superpixel 수준의 entropy는 superpixel을 구성하는 픽셀들의entropy를 더한 것임
- fully connected Conditional Random Field는 모든 pixel에 대해 probability score map을 제공함
- 따라서, fully connected Conditional Random Field를 이용하여 uncertainty를 계산함 (deep learned model을 이용하여 uncertainty를 구한 것이 아님)deep learned model을 이용한 segmentation 결과에 fully connected Conditional Random Field(CRF)를 적용함
3.1.5 Class Specific Selection of Pixels/SuperPixels:
- 이미지들 내 class별로 픽셀 수의 불균형이 존재하지만 class 별로 동일한 수의 픽셀들을 취하는 것이 이상적임
- 이를 위해서 다음과 같은 방법을 사용함
- labeled data로 model을 학습시킴
- model로부터 얻어진 feature vector를 사용하여 labeled image에서 모든 픽셀들을 represent함
- 이러한 feature vector들을 사용하여 feature space를 구성함
- Unlabeled image에 대해 모든 class 평균을 사용하여 각 픽셀의 유사도(cosine similarity)를 계산함
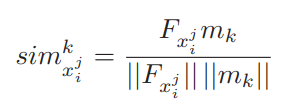
$F_{x^{j}_{i}}$ :: model로부터 얻어진 xi이미지의 j번째 픽셀의 feature vector
$m_k$ :: k번째 class를 나타내는 feature vector
- 다음으로 각각의 픽셀에 대해 가장 비슷한 category를 할당함
- 각각의 개별 class에 있는 픽셀들의 entropy를 구함 (class 자체의 독립적인 entropy를 구하는 것을 대신하여)
- 각각의 class들로부터 독립적으로 높은 entropy 픽셀들을 선택함3.1.1 Image-level Entropy:image xi 안에 있는 모든 픽셀에 대한 uncertainty를 더함
4. Experimental Results
semantic segmentation을 위한 자신들의 entropy에 기반한 active learning method들을 평가함
4.1 Datasets and Experimental setting
Cityscapes
- (1024 X 2048) → (512 X 1024) - 학습 시, (1024 X 2048) - test 시
- 30 classes
- iterations :: 30K
- 2975 장의 train data
- 1175 장 → 초기 model 학습용
- 1800 장 → 300장씩 추가하여 active learning을 진행 (group size : 6)
- 500 장의 valid data
model
- ICNet (high-resolution image에서 real-time semantic segmentation 시 많이 쓰는 model)
Mapillary
- (1920 X 1080)
- 66 classes → 19 classes (Cityscapes)와 공통인 classes
- iterations :: 90K
- 3000장씩 추가하여 active learning을 진행 (group size: 6)
annotation pixel ratio :: 10%
superpixel size :: 1400
base learning rate :: 0.01
poly learning rate policy :: 0.9
momentum :: 0.9
weight decay :: 0.0001
batch size :: 8
framework :: Caffe
full connected CRF 의 parameter들은 Deeplab과 비슷한 setting을 함
- w2 = 3, ry = 3
- w1, ra, rb → cross validation (small subset 100개를 사용)
4.2 Results on Cityscapes dataset
4.2.1 Image Level Annotations
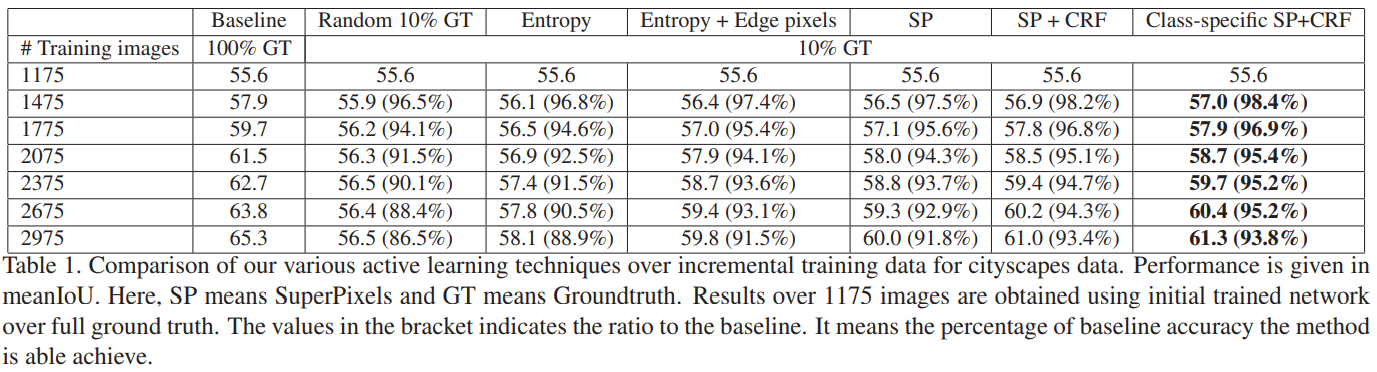
- Baseline :: 100% annotation된 데이터를 추가하였을 때의 성능
- Random 10% GT :: random으로 10%의 픽셀을 선택하여 annotation 후의 성능
10% 이외 나머지 픽셀들은 model이 predict한 결과 그대로 사용함
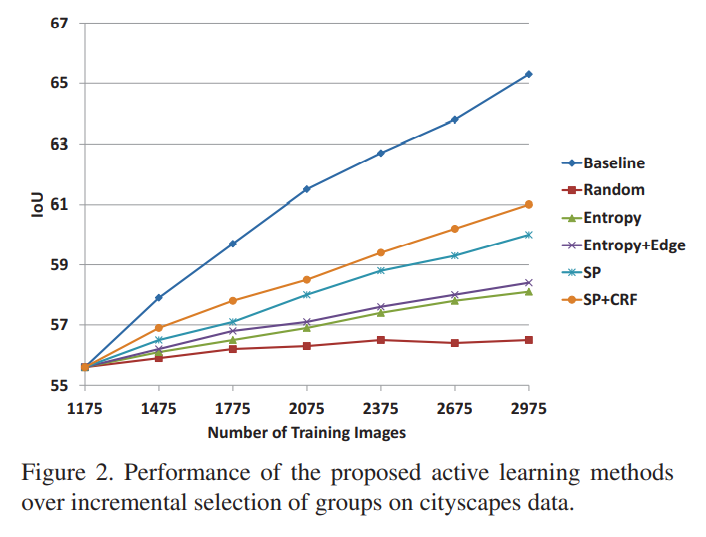
- Baseline이 가파르게 증가하는 것은 초기 그룹에 높은 uncertainty를 가진 이미지가 존재하기 때문
4.2.2 Pixels/Region Level Annotations

- ground truth와 비교하여 segmentation results에서 틀린 부분이 SP+CRF에서 더 많이 보임
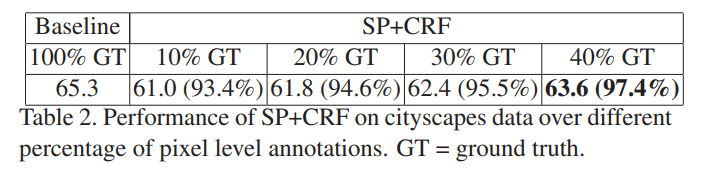
- annotation의 비율을 늘릴 수록 증가함
- 40%만하여도 100%하였을 때의 97.4%의 성능을 냄
4.3 Results on Mapillary Dataset
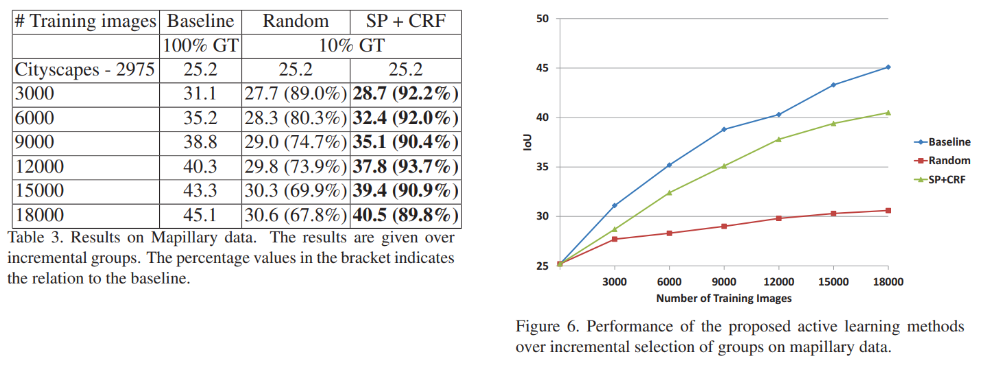
- dataset이 다름에도 transfer learning하였을 때의 결과도 우수함
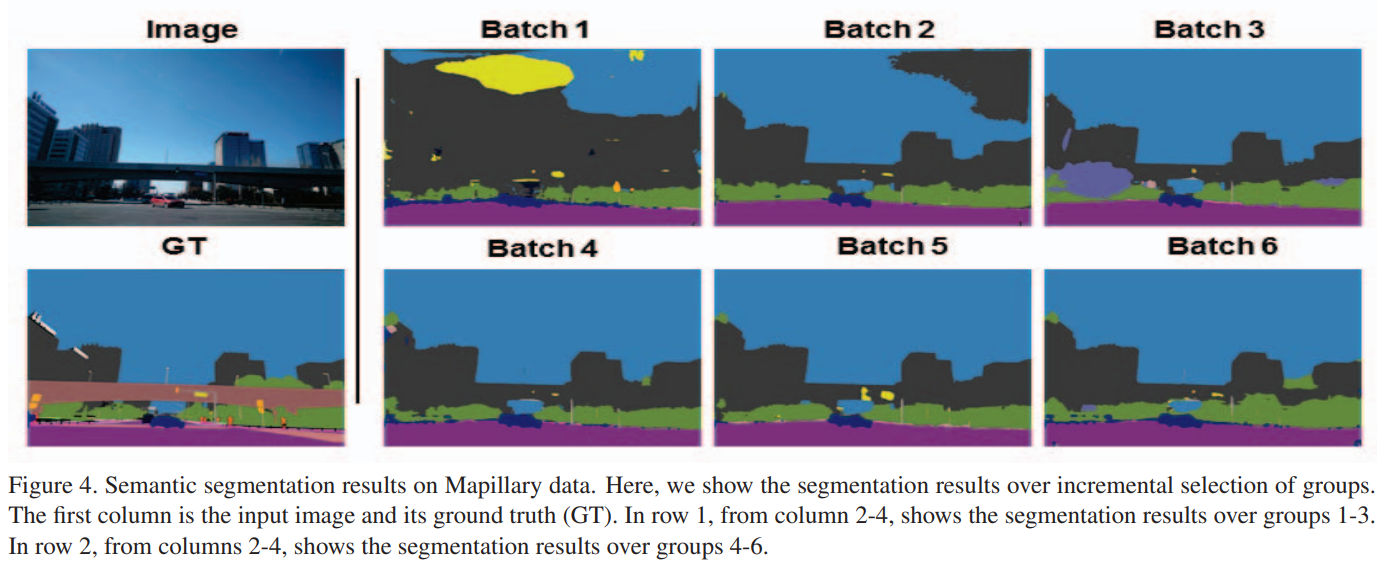
- 각각 3000개의 이미지가 추가될 때 마다 validation 성능의 변화

- 10% label만을Transfer learning 하였을 때의 결과 시각화

oracle이 annotation을 할 때 coco annotation tool을 사용
- larger region :: watershed algorithm
- smaller/narrower region :: magnetic lasso tool
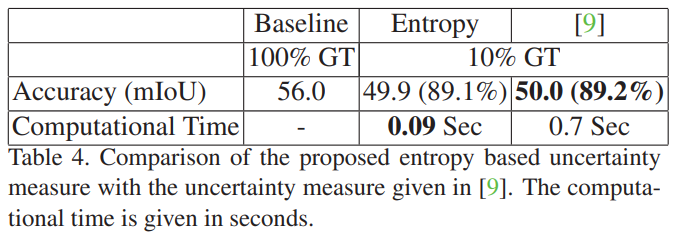
Cost-Effective Active Learning for Melanoma Segmentation
- uncertainty 측정방법과 비교함
- 성능은 비슷하나 계산 속도면에서 우월함
성능이 좋은 class가 다름
Entropy based method :: person, vehicle classes (truck, bus, train, motorcycle, bicycle)
Uncertainty measure :: traffic light, traffic sign, terrain, sky and rider
- 히비스서커스 -
'Theory > Computer Vision' 카테고리의 다른 글
| [Calibration] Bridging Precision and Confidence: A Train-Time Loss for Calibrating Object Detection 논문 정리 (1) | 2023.11.23 |
|---|---|
| [Active Learning] Cost-Effective Active Learning for Melanoma Segmentation 논문 리뷰 (0) | 2022.08.23 |
| [WSSS] CIAN 논문 정리 (0) | 2022.03.10 |
| [WSSS] SEC 논문 정리 (0) | 2022.02.21 |
| [WSSS] OC-CSE논문 정리 (0) | 2022.02.14 |



