
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Decision Boundary
- HookNet
- 프로그래머스
- Pull Request
- docker attach
- GIT
- logistic regression
- IVI
- 사회조사분석사2급
- 코크리
- 백신후원
- docker exec
- aiffel exploration
- WSSS
- 히비스서커스
- 기초확률론
- vscode
- numpy
- 오블완
- 도커
- cocre
- AIFFEL
- 티스토리챌린지
- Jupyter notebook
- CellPin
- docker
- cs231n
- Multi-Resolution Networks for Semantic Segmentation in Whole Slide Images
- ssh
- airflow
- Today
- Total
히비스서커스의 블로그
[Calibration] Bridging Precision and Confidence: A Train-Time Loss for Calibrating Object Detection 논문 정리 본문
[Calibration] Bridging Precision and Confidence: A Train-Time Loss for Calibrating Object Detection 논문 정리
HibisCircus 2023. 11. 23. 16:31이 글은 CVPR 2023년에 accept된 Bridging Precision and Confidence: A Train-Time Loss for Calibrating Object Detection 란 논문을 읽고 정리한 글입니다.
1. Introduction
1) 문제 제기
DNN(Deep Neural Network) 의 발달로 Image Classification, Semantic Segmentation, Object Detection 분야에서 많은 발전이 이루어졌으나 Prediction에 대해 overconfident한 경향이 존재
이러한 문제는 전자 건강 기록, 자율 주행, 크로모솜 관련 연구에서 incorrect prediction을 가지나 high confidence할 경우 심각한 문제를 초래함
주요 원인은 training with zero-entropy supervision 때문인데 다시 말하자면 애매한 ground truth에 대해 확실한 class로 학습하게 되기 때문임
2) 해결 방안
제안된 해결 방안으로는
1. post-processing step → held-out validation set을 학습
- 장점
- 구현하기 간단
- 단점
- architecture와 data-dependent함
- 실제 상황에서 사용이 가능하도록 준비되기가 어려움
2. train-time calibration method
- 이전
focal loss가 cross entropy loss에 비해 더욱 calibration이 잘 되도록 학습이 가능하며 temperature scaling과 같이 활용할 경우 SOTA가 가능함 (J Mukhoti et.al., NeurIPS 2020)
Focal Loss 간략 정리
요약
- one-stage detector의 성능 개선을 위해 고안됨
문제점
- 기존의 cross entropy loss는 easy example과 hard example 모두에게 동일한 weight을 부여하여 hard negative example에 대한 학습이 이루어지기 힘듦
해결 방안
- easy example weight을 줄이고 hard negative example에 대한 학습에 초점을 맞추는 cross entropy loss의 확장판

상세 내용
- γ는 focusing parameter로 easy example에 대한 loss 비중을 낮추는 역할
- γ가 증가함에 따라 Hard 케이스보다 Easy 케이스에서 더 많은 weight이 떨어짐을 이용하여 기존의 Negative 케이스에 의한 loss가 누적되는 문제를 해결
- 최근에는 auxiliary loss를 사용
- predicted label과 non-predicted label의 class confidence를 모두 calibration하는 auxiliary loss인 MDCA loss (Multiclass Difference of Confidence and Accuracy) 를 사용 (R Hebbalaguppe et.al., CVPR 2022)
3) 논문에서 기여한 점
object detection은 안전 기준을 요구하는 application에서 많은 점유율을 차지고 있기 때문에 in-domain, out-domain prediction에서 well-calibrated 되는 것이 중요함
이 논문에서 제안하는 것은 miss calibration에 대해 penalty를 부여하는 auxililary loss인 BPC (Bridge the model’s precision with the predicted class confidence Loss)를 제안함
2. Related work
validation parameter
| validation set | parameter | |
| Post-hoc Method | O | a few |
| Train-time calibration Method | X | all |
1) Post-hoc Method
Temperature Scaling
σ(Zk/T),k=1,2,...,i
cross entropy loss안에 들어갈 값을 parameter T로 나누어 scaling을 해주어 prediction이 calibration 되도록 함 (T는 hold-out 을 이용하여 얻음) (C Guo et.al., ICML 2017)
단점
- dense prediction task에서 결과가 좋지 않은 경향이 있음
- in-domain prediction만 calibration 됨
- out-domain에서도 잘 적용하려면 validation set을 transform 해야 함
2) Train Time Calibration Method
학습 시 overconfidence하게 만드는 zero-entropy supervision의 대표적인 예시로는
NLL (Negative Log-Likelihood)
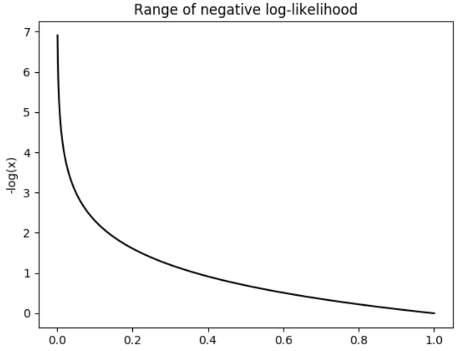
- 방식
- prediction을 1로 가까이 예측할수록 loss의 값이 줄어들어 model이 over confidence하도록 하게 함
학습 시 auxiliary loss를 추가하여 calibration에 도움이 되도록 하는 방법으로는
DCA (Difference between Confidence Accuracy) Loss
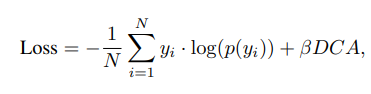
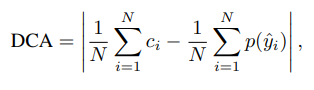
- 표기 설명
- N은 미니 배치에 포함된 샘플 수
- c는 각 샘플에 대한 flag로서
- yi (실제 레이블)가 yi^ (예측 레이블)과 일치할 때 1이고, 일치하지 않으면 0
- 작용 설명
- 아래와 같은 상황에서
- entropy loss는 줄어들지만 accuracy는 바뀌지 않을 때 다시 말하면,
- training data에 대해서는 confidence가 높지만 실제 정확한 예측을 하지 않는 경우(overfitting 발생 시)
- 딥러닝 모델에 페널티를 주어 calibration 문제를 해결함
- 평균 예측 confidence를 정확도와 일치하도록 만듦
- 아래와 같은 상황에서
- 한계
- prediction accuracy term에서는 미분이 불가능함 (argmax 과정이 들어가기 때문)
Hilbert space mapping
- Hilbert space란?
- 수학에서 벡터 공간의 특별한 종류 중 하나, 무한 차원을 가지며 내적 연산이 정의된 공간
- 작용 방식
- 힐베르트 공간에 맵핑 시 커널 트릭을 활용할 수 있는데 이를 통하여
- 입력 공간에서 연산을 내적 연산으로 변환하여 계산 효율성을 높일 수 있음
- calibration error를 측정하는데 사용하는 함수를 높은 유연성과 성능으로 정의할 수 있음
- 힐베르트 공간에 맵핑 시 커널 트릭을 활용할 수 있는데 이를 통하여
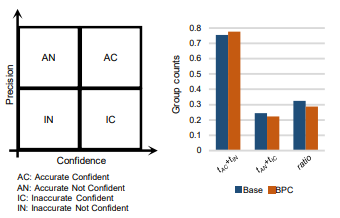
AvUC (Accuracy versus Uncertainty Calibration) Loss
(R Krishnan et.al., NeurIPS 2020)
- 요약
- AC (Accurate and Confidence) 와 IU (Inaccurate and Unconfidence)의 비율을 높이도록 loss를 추가
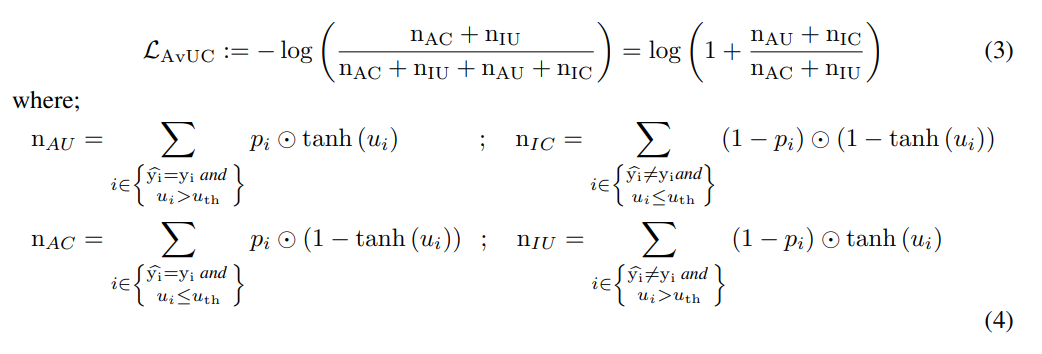
MDCA (Multi class difference of Confidence and Accuracy) Loss
(R Hebbalaguppe et.al., CVPR 2022)
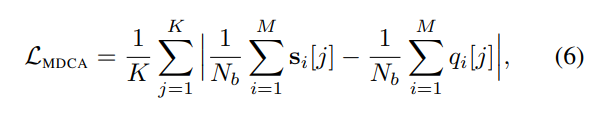
- 표기 설명
- k: 클래스 수
- Nb: 미니 배치의 샘플 수
- M: bin의 수
- si[j]: i번째 bin의 j번째 클래스에 할당한 confidence
- qi[j]: i번째 bin의 실제 클래스가 j인 경우 1, 그렇지 않으면 0 (Indicator function)
- 장점
- DCA Loss와 달리
- argmax를 구하는 prediction의 값이 빠졌기 때문에 미분이 가능함
- 모든 클래스의 predicted confidence를 calibrate하기 위함
- DCA Loss와 달리
MbLS (Margin-based Label Smoothing) Loss
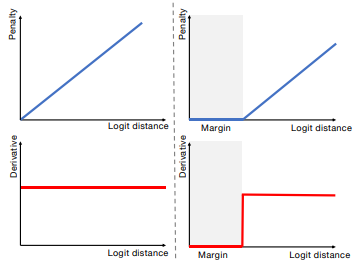
- 작동 방식
- 왼쪽 그림의 경우, 항상 역전파 됨
- logit의 거리와 관계없이 역전파가 항상 일정하게 유지됨 → 모든 로짓을 동일한 클래스로 예측
- 오른쪽 그림의 경우, gradient가 margin을 초과하는 경우에만 역전파됨
- logit의 거리가 일정 이상만 역전파가 됨 → 유연한 학습이 가능하게 됨
- 왼쪽 그림의 경우, 항상 역전파 됨
- 장점
- 기존 loss의 전반적인 강력한 penalty를 완화해주는 효과
3) Other Method
model calibration with OOD detection 방법으로 제안된 방법들 중에서
ReLU function
- 요약
- Out-Of-Distribution (OOD)에서 Model Calibration 시 ReLU activation이 overconfident prediction을 유발함
- 다시 말하면
- ReLU 네트워크가 훈련 데이터로부터 거리가 먼 입력에 대해 해당 입력이 특정 클래스에 속할 것이라고 자신하는 경우가 있음
early layers in CNN
- 요약
- OOD는 주로 CNN의 초기 layer에서 찾아질 수 있음
- 제안한 것
- OOD를 감지하기 위한 방법으로 특징 맵의 스펙트럼을 계산
- 특이값 분해
- 의미
- mxn 행렬을 세가지 행렬의 형태로 분해할 수 있는데 특이값 행렬은 mxn 행렬의 주요 정보를 담고 있음
- 차원 축소
- 행렬의 의미 분석
- mxn 행렬을 세가지 행렬의 형태로 분해할 수 있는데 특이값 행렬은 mxn 행렬의 주요 정보를 담고 있음
- 의미
- 상세 설명
- 스펙트럼은 특이값 분해(SVC - singular value composition)를 사용하여 계산된 특이값의 벡터로 정의
- 정규화된 log Spectrum ⇒ 특징 맵에 대한 spectral signature 라고 정의
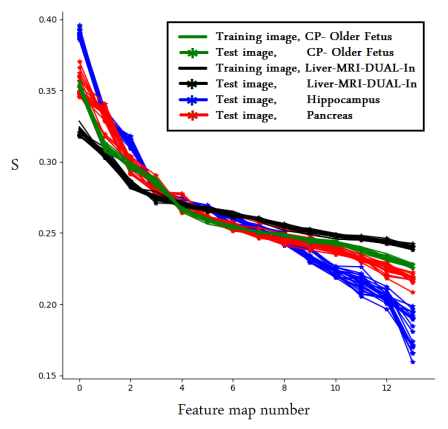
- 네 개의 데이터에 대한 spectral signature
- CP와 Liver는 train
- Hippocampus, Pancreas는 test
- train에 대해서는 명확한 spectral signature를 갖지만 test는 아님
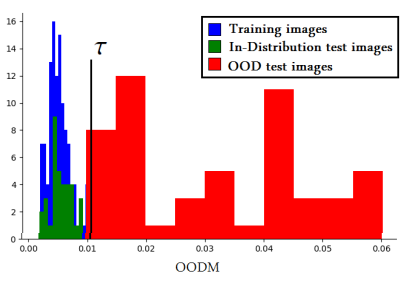
- spectral signature의 비유사성을 기반으로 OOD를 감지하는 것을 제안
- OODM (Out-Of Distribution Measure)은 테스트하는 데이터의 spectral signature가 train 데이터 안에서 가장 가까운 이웃과의 Euclidean Distance를 나타냄
3. Method
3-1. What is Calibration?
예측된 확신도(Predicted Confidence)와 샘플이 정확할 가능성(Likelihood of the sample being correct)이 일치하는 정도
confidence: s, correct: c
over confident :: c < s
under confident :: c > s
- Classification

- Object Detection

3-2. Measuring Calibration
Classification → accuracy
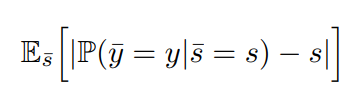
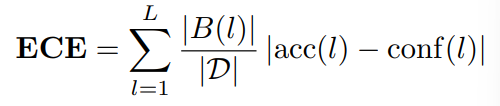
D는 전체 데이터 수
B는 l번째 영역에서 집합
Object Detection → precision
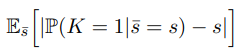
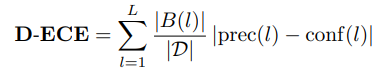
D는 전체 object instance의 수
B는 l번째 영역에서 object instance의 집합
- 왜 precision을 활용하는가? (F Küppers et.al., CVPRW 2022)(나머지는 prediction을 하지 않으므로 confidence가 없음)
- ⇒ precision이 True Positive와 False Positive를 포함하기 때문
3-3. BPC: Train-time Calibration Loss for Detection
motivation
- DNN은 In-Domain과 Out-Domain에서 incalibrated 됨
⇒ 정확한 예측에 대해 높은 confidence를 부여하고
부정확한 예측에 대해 낮은 confidence를 부여하는 학습 방식이 없기 때문
따라서, 이에 기반하여 detection모델을 보정함
- train-time method로 auxiliary loss function을 추가한 것
- mini-batch 단위로 작동하고 미분 가능하며 다른 loss와 사용 가능
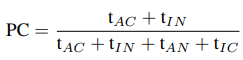
t는 각 경우에서 detection 의 수
수식으로 살펴보면
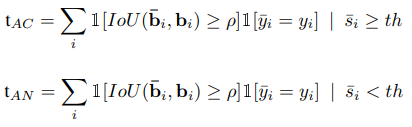
이때, indicator function은 미분이 불가능 (backprop을 할 수 없으므로 학습에 쓸 수 X)
이를 위해서 tanh 근사를 통해
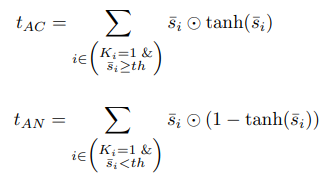
미분이 가능하도록 해줌
이제 loss로 만들어주면
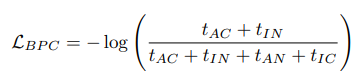
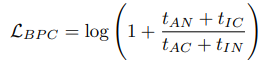
AN과 IC가 줄어들면 loss가 줄어들도록 되어 calibration이 잘되도록 학습이 됨
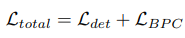
4. Experiments & Results
Dataset
- MS-COCO (80개의 object category를 포함)
- train 118,000 장
- valid 5,000 장
- test 41,000 장
- CorCOCO
- MS-COCO의 손상된 버전
- Cityscapes (8개의 카테고리)
- train 2,975 장
- valid 500 장
- Foggy Cityscapes
- 안개가 낀 날씨를 시뮬레이션
- Sim 10k
- train 8,000개
- valid 1,000개
- test 1,000개
- BDD 100k
- train 70,000개
- valid 10,000개
- test 20,000개
⇒ out-domain scenario 평가를 위해 validation의 일부만 사용
Dataset (Post-hoc)
- MC-COCO
- Object365
- Cityscapes
- BDD100k 일부
- Sim10k
- 해당 validation 사용
Implementation Detail
기본적으로 Deformable-DETR(D-DETR)을 사용
DETR 간단하게 알아보기
등장 배경

기존의 object detection 방식
pre-defined anchor를 활용
- 예측한 bounding box와 ground truth의 관계가 many-to-one
- 이를 위해 post-processing 방법인 NMS (Non Maximum Suppression)을 사용

DETR의 detection 과정
hand-crafted anchor를 사용하지 않음
- bounding box와 ground truth의 관계가 one-to-one (post-processing 필요 X)
- Hungarian algorithm을 사용하여 두 집합 사이의 일대일 대응 시 가장 비용이 적게 드는 이분 매칭을 찾는 알고리즘을 활용
모델의 구조
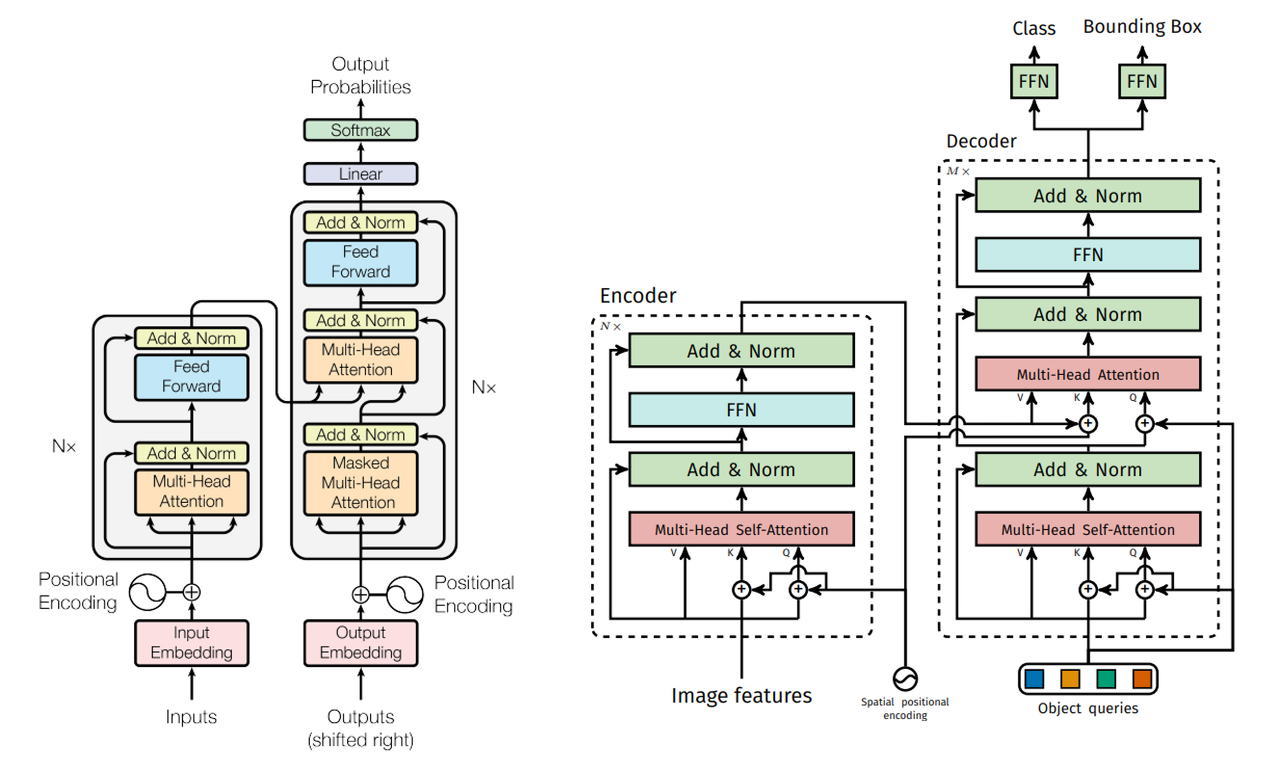
Vanilla Transformer (왼쪽), DETR Transformer (오른쪽)
Transformer의 구조를 활용하되 5가지 차이점이 존재함
1. encoder의 입력
- origin encoder: 문장에 대한 embedding
- DETR encoder: 이미지 feature
2. positional encoding
- origin: positional encoding을 더해줌 (입력 embedding과 상관없이 동일한 값을 출력하는 permutation invariant 성질을 가졌기 때문)
- DETR: 기존의 positional encoding을 2 Dimension으로 일반화시켜 spatial positional encoding을 수행 (2 Dimension의 입력을 받기 때문)
3. decoder의 입력
- origin: target embedding
- DETR: object query
4. attention 연산
- origin: 첫 번째 attention 연산 시 masked multi-head attention을 수행
- DETR: multi-head self-attention을 수행
5. Decoder 이후의 head 수
- origin: 하나의 head
- DETR: 두 개의 head
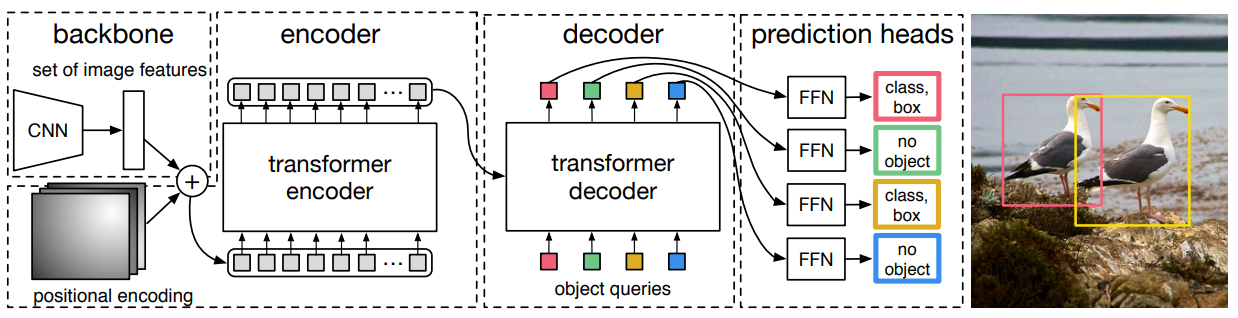
Deformable-DETR 간단하게 알아보기
DETR의 한계
- 수렴이 오래 걸림
- 작은 물체에 대한 성능이 낮음
Deformable Attention Module
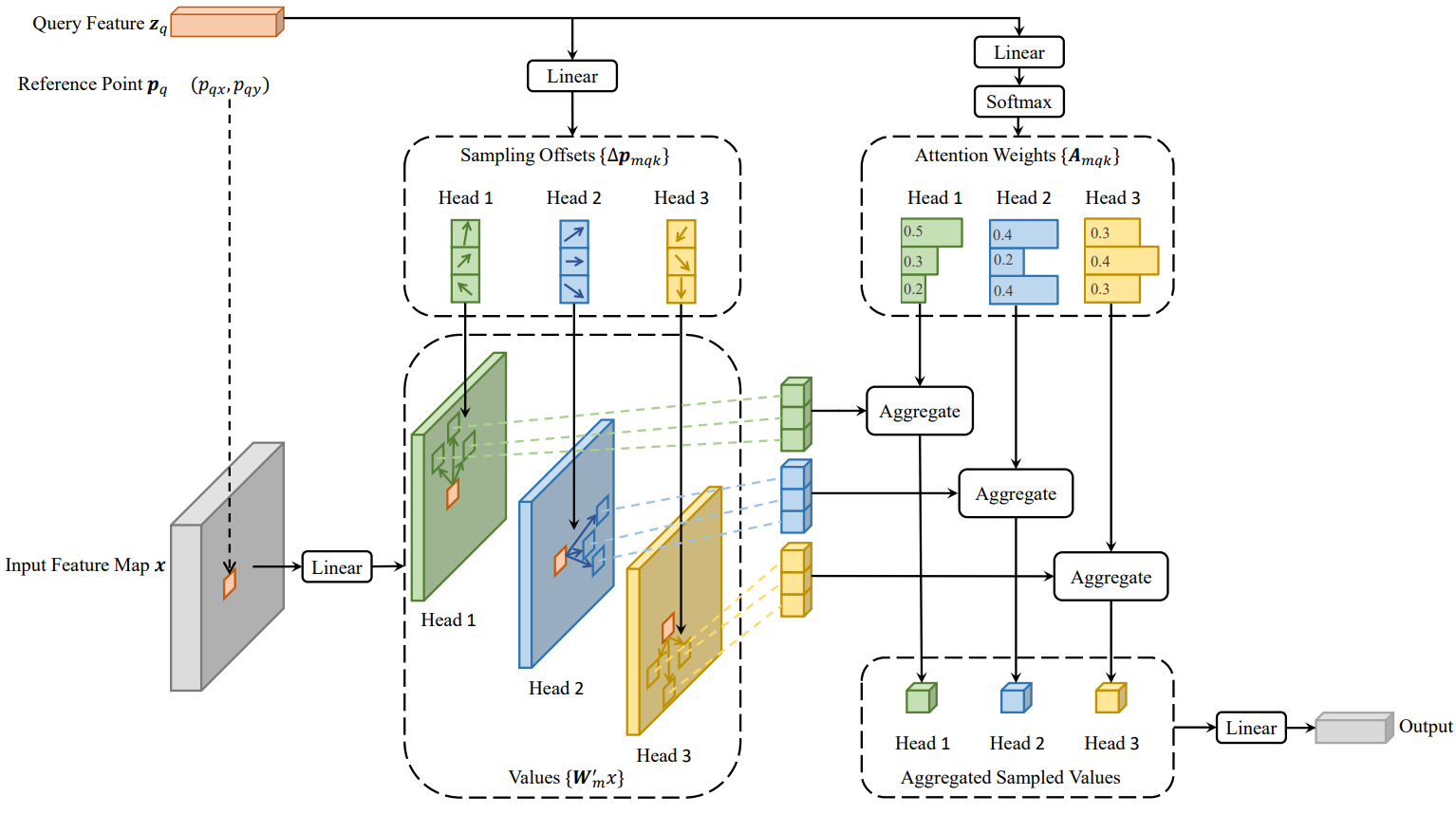
수렴이 오래 걸리는 이유?
- transformer attention을 적용하기에 가능한 모든 공간 위치를 살펴봄
deformable attention module의 방식
- feature map의 공간 크기에 관계없이 기준점 주변의 작은 key 샘플링 지점 집합에만 관심을 가짐
- 이를 통해, 각 query에 대해 수렴 및 feature space 해상도 문제를 완화할 수 있음
Multi-scale Deformable Attention Module
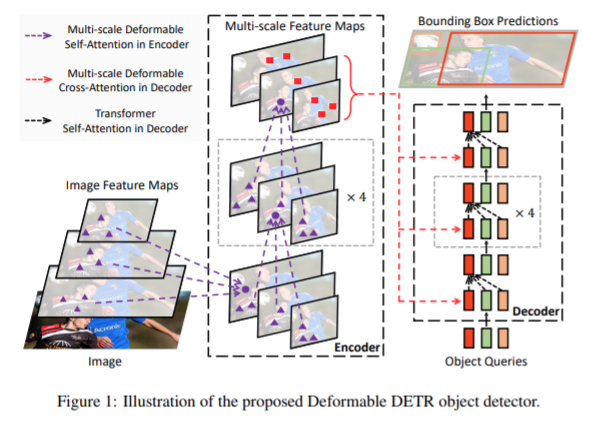
작은 물체를 못 찾는 이유?
- multi-scale feature를 사용하지 않기 때문 (복잡도 때문에 불가)
multi-scale feature 사용 시
- high resolution feature map을 detect 할 수 있음
- sampling location을 정해서 attention 해주는 역할 (FPN 없이)
loss fucntion으로는 focal loss를 사용
localization에 대해 generalized IoU 및 L1 loss를 사용
Post-hoc 방법 뿐 아니라 calibration loss를 활용하는 MDCA과 MbLS의 성능도 비교
Evaluation
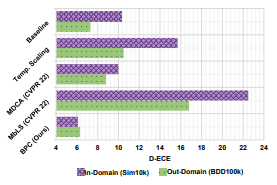
In-Domain과 Out-Domain 모두에서 D-ECE (Detection Expected Calibration Error)를 측정
4.1 Results
Real and Corrupted domain
in-domain: COCO, out-domain: CorCOCO
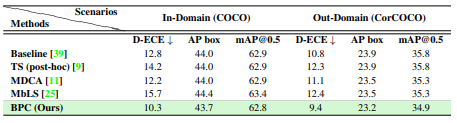
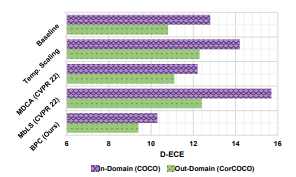
Weather domain
in-domain: Cityscapes, out-domain: Foggy Cityscapes

Scene domain
in-domain: COCO, out-domain: BDD100
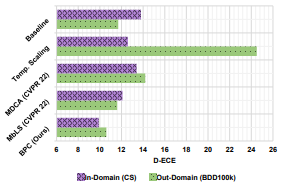
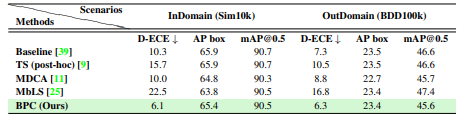
Synthetic and Real domain
in-domain: Sim 10k, out-domain: BDD 100k
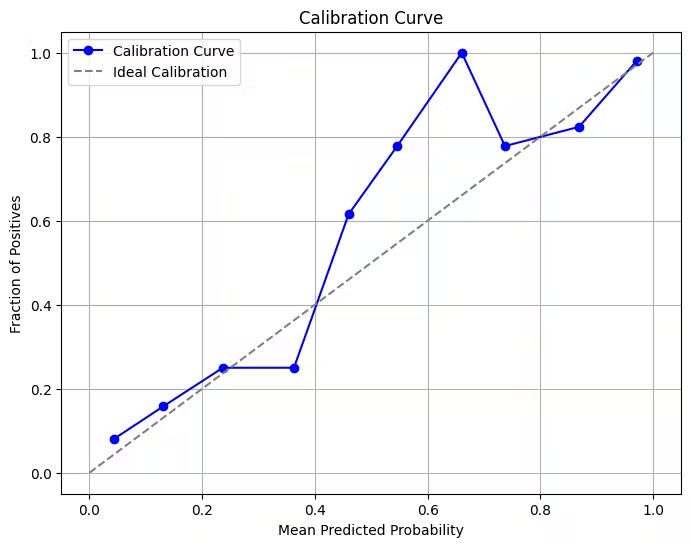
정성적인 결과

calibration plot

4.2 Ablation & Analysis
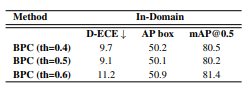
Dataset - Sim 10k
Score Threshold ⇒ 0.5
Batch Size ⇒ 2
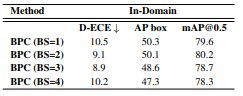
⇒ batch 의 증가에 따른 detection의 정확도에 미치는 영향은 거의 없음
또한, Calibration에도 큰 영향을 주지 않음
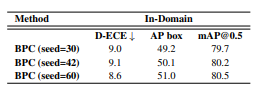
Random Weight Initialization ⇒ seed 42
5. Conclusion
Calibration을 위한 auxiliary loss로 BPC를 제안함
- AC와 IN을 높이고, AN, IC를 낮추는 방향으로 학습
대규모 데이터 셋에서 calibration이 잘 수행됨을 확인
'Theory > Computer Vision' 카테고리의 다른 글
| [Active Learning] Cost-Effective Active Learning for Melanoma Segmentation 논문 리뷰 (0) | 2022.08.23 |
|---|---|
| [Active Learning] Region-Based Active Learning for Efficient Labeling in Semantic Segmentation 논문 정리 (0) | 2022.08.22 |
| [WSSS] CIAN 논문 정리 (0) | 2022.03.10 |
| [WSSS] SEC 논문 정리 (0) | 2022.02.21 |
| [WSSS] OC-CSE논문 정리 (0) | 2022.02.14 |



